





.jpg)
Agents are now on the precipice of taking on long‑running, end‑to‑end tasks. They can resolve support tickets, write code, push PRs, and even complete entire sales account plans. But as agents tackle more complex tasks, they’re increasingly constrained by the model’s context window. As your data crowds the context window, agents are forced to make tradeoffs, capping results, summarizing aggressively, or dropping details, which artificially limits how much real work they can take on. Even with models that support large context windows, we still see agents lose attention, and the cost of long-context tasks remains high.
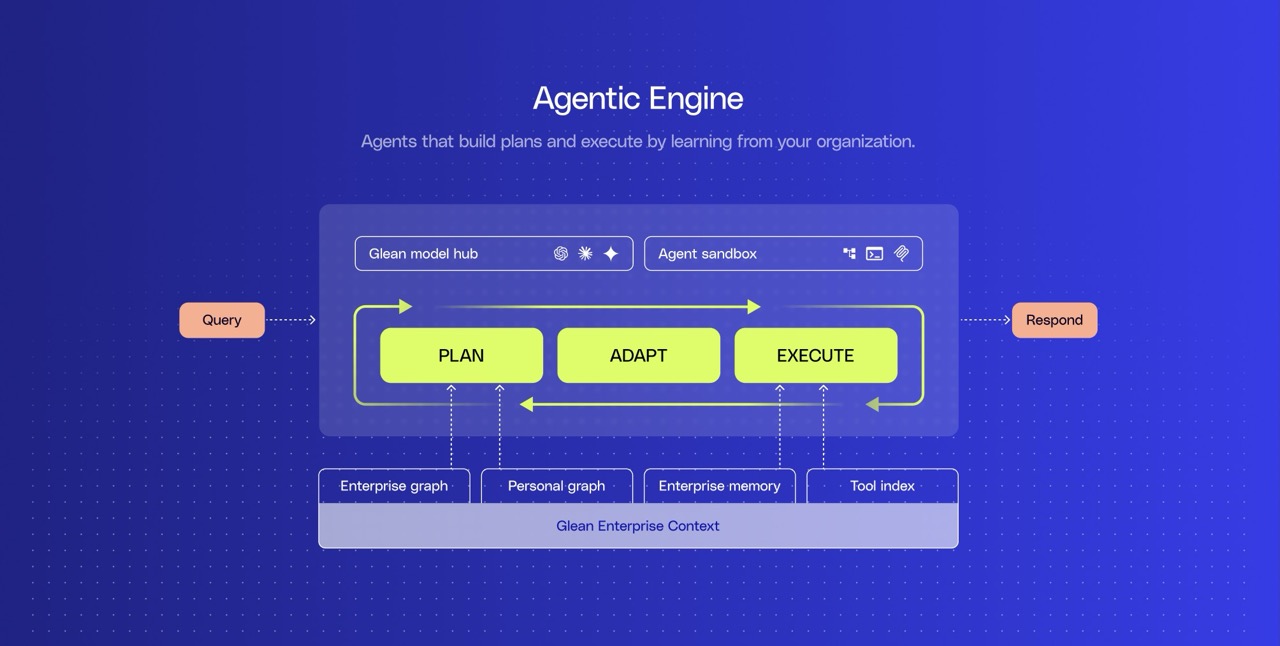
What we’ve found is that if you give an agent a sandbox, a virtual computer equipped with a file system, command line, code runtime, and tool index, it can use that environment to expand its effective short‑term memory and process far more data than LLM context windows allow. Agents can read from the file systems directly, making the data fully iterable so the agent can pull what they need at each phase of execution, rather than trying to fit everything into the context window.
In the enterprise, we’re seeing this unlock new analytical use cases, including aggregating large‑scale datasets that were previously out of reach for agents. In this blog, we’ll walk you through a real use case this opens up.
Complete analysis of all your structured and unstructured data
Many routine tasks for sales leaders sound simple: "Review all my Q4 opportunities to analyze pipeline health." In reality, this requires pulling together thousands of data points from systems of record and productivity apps to get the full picture.
As the agent runs and retrieves the content needed for the pipeline report, it nears the limit of the model’s context window and spins up an agent sandbox.
The agent sandbox works alongside Glean’s enterprise context, bringing in structured opportunity data from Salesforce alongside unstructured Gong call transcripts, Teams messages, Outlook emails, Word documents, Powerpoint presentations, and more.
Glean makes it possible for the agent to make sense of this data by mapping it in the Enterprise Graph, which links customers, account managers, and activity across all your business apps. That way, only relevant, high‑quality data lands in the sandbox, and is used at each stage of agent execution, preventing the agent from context overload and interference. The sandbox lets agents extract maximum value from large amounts of context, but only when it’s filled with the right context to begin with.
The agent sandbox includes a Python runtime for analytics and data processing. As the agent runs, it can use code execution to assess pipeline risk, run sensitivity analyses, detect outliers, and generate a ranked list of opportunities with predicted win probabilities.
The real breakthrough is that this analysis isn’t limited to the cleaned, structured data that shows up in CRM reports: the agent can pull in and analyze unstructured data from all your customer conversations, conversations that used to be out of reach to complete the analysis. Now your forecast reflects the actual story happening with customers, not just the narrow slice captured in structured data fields.
Lessons from engineering short-term memory management
Before we built sandboxes, LLM context windows were the only short-term memory Glean Agents had available. Even as context windows expanded with each model release, agents still needed efficient and structured short-term context management to achieve performance.
AT Glean, we designed a classification hierarchy for data flowing into the context window. This allowed agents to distinguish between user inputs, system instructions, and tool outputs across different parts of a conversation. These heuristics helped agents decide what content to trim while preserving critical facts and instructions. Sandbox uses this same hierarchy for a more powerful approach. Instead of discarding information, an agent keeps data it immediately needs in the LLM context window and stores extra data in the filesystem for on-demand access later. With the sandbox, memory management shifted from deletion to persistence.
We also built selector tools that let agents load specific snippets of large documents into memory based on company-specific semantic similarity. This allowed agents to understand long documents quickly without the cost of reading everything upfront. The sandbox filesystem powers a similar strategy with greater capacity. With sandboxes, we can use the selector tools to quickly hone in on the right snippets but now pair it with greedy materialization, analyzing the full document, revisit specific sections, or write code to analyze them.
We exposed advanced filters in Glean search tools, so agents could make better, faster use of the data, allowing them to specify date ranges, document types, and ranking signals like semantic similarity and popularity. These same advanced filters now serve to make the sandbox more efficient.
While our early systems were effective, they were brittle. A framework that worked for GPT-5 might fall short for Claude Sonnet 4.5. Even minor updates (e.g., GPT-5.1 to 5.2) caused large variations in performance. This is because memory in the context window relies on model attention, which changes every update. As a result, the LLM’s interpretation of summaries, instructions, and task states varies across versions, leading to quality drift even if the agent system remains unchanged. Maintaining quality across models meant continuously tuning memory. This is why agents don’t need larger context windows, the problem of brittle short-term memory would still remain. What they need instead are sandboxes.
This brittleness was the hidden cost of treating the context window as the only form of memory. Sandboxes let us move that state out of the fragile context window and into a stable environment the agent can reliably work in. Many of our earlier investments in classification, retrieval, and ranking continue to be relevant today. At the same time, much of the work spent on aggressive truncation, compression, and token-budget micromanagement went away with sandboxes.
How we made the agent sandbox secure
Security is built into the agent sandbox from the ground up. Every sandbox runs in an isolated environment inside your own VPC, with strict resource limits, scoped file systems, and session-level isolation. Data, code, and intermediate artifacts from one session never leak into another. Sandbox network access is disabled by default and will be fully configurable in the future, minimizing exposure while giving tight control when external connectivity is needed. Because tools and LLM calls are still routed through the same orchestration paths as before, sandbox inherits all of Glean’s existing guardrails, permissions, and governance controls.
Models and context work better together with the agent sandbox
Agent sandboxes don’t replace better models or richer context. They make both more useful together. When you give agents a sandbox, they stop fighting the context window and start taking on more work than before.
For a work AI platform where capable agents meet complete company context, sign up for a demo of Glean today!
Availability: Glean agent sandboxes are coming soon.



