









- Context graphs are advanced models that connect enterprise entities (like people, documents, and systems) with the actual actions and events between them, enabling AI to understand not just what exists but how work truly gets done—including the flow, variability, and intent behind processes.
- Building effective context graphs requires deep integration with enterprise tools, robust knowledge and personal graphs, and careful aggregation of anonymized activity traces, allowing the system to identify high-value, repeatable processes while preserving privacy and security.
- Glean’s approach continuously evolves context graphs by learning from both human and agent actions, ensuring that AI agents remain grounded in real, up-to-date organizational processes and can autonomously adapt to changing workflows and business needs.
Context graphs are getting a lot of attention right now, with investors calling them a “trillion-dollar opportunity.”
That’s because while AI models can now use tools, they still lack the process knowledge needed to actually automate work. Systems of record capture decisions, but the real work happens in meetings, chats, emails, and docs. Without a structured view of how work actually gets done, AI cannot automate it reliably.
With all the hype, social posts keep circling the same two questions: what exactly is a context graph, and how do you build one? In this blog, we’ll lay out Glean’s approach to building context graphs and explain why we took the path we did.
What are context graphs?
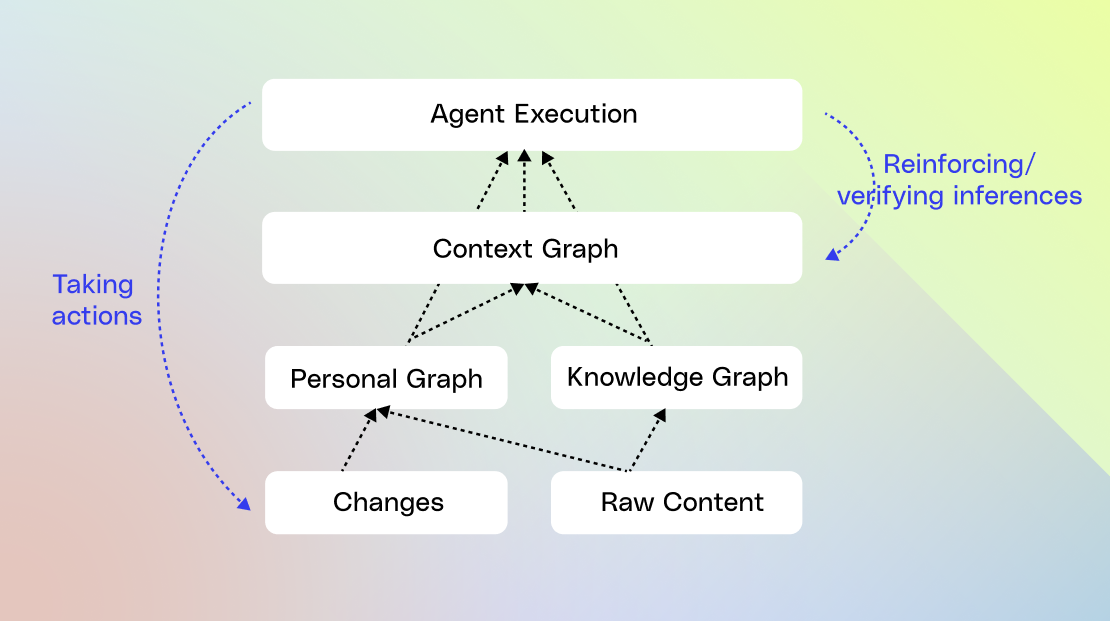
A context graph is a model that connects your enterprise entities (people, documents, tickets, systems) with the temporal traces of actions and events between them. It then surfaces actionable insights from those traces so AI understands how work actually gets done.
Context graphs help AI answer questions like:
- “How do P1 incidents usually get resolved here?”
- “What are the most common escalations about product X?”
- “What typically happens between ‘pilot created’ and ‘deal closed’?”
- “What does ‘onboarding complete’ actually mean for this team?”
- “How long does typical deployment take and why?”
Current agents have difficulty with end-to-end processes or long-term tasks (those spanning weeks or months) that require synthesizing knowledge from multiple, disparate systems.
When you connect multiple tasks that span different events, you need to bring together information from various sources and from many people who each execute the work a bit differently, with local exceptions and one-off edge cases baked into their process. But systems of record typically only show the current state and rarely capture this execution variability or the full historical context, so relying on that incomplete view can lead to blind spots and suboptimal outcomes.
Instead, having an internal model of your organization’s real processes—a context graph built from actual traces of actions—becomes the best proxy for learning both the structure to follow and the intent behind the work.
From “what” to “how”
A context graph describes the flow of work by shifting from describing “what” exists to describing “how” change happens:
- “What”: Traditional data and knowledge systems model things: customers, tickets, docs, people, systems.
- “How”: A context graph models behavior: who did what, in which apps, in what order, and with what effect.
The “how” is described by transforming actions into a first-class entity in the graph:
- Nodes: (aka User and Agent Actions with rich data traces) “created,” “viewed,” “approved,” “escalated,” “commented on,” “resolved,” each with timestamps and rich metadata about the changes.
- Edges: The edges are causality and correlation. “Message A” triggered “Update B” at probability P.
We chose to have Glean model this way in order to attach predictive power to a sequence of activities, so we can suggest what step is likely to happen next without hard-coding a flow. What we end up with is a distribution of likely paths, giving the agent the autonomy to pick the most probable one for the scenario.
Now, layered on top of these process paths are derived insights—a reasoning behind why “Path A” differed from “Path B.” This enables us to encode not just the “how” but also a probable “why,” which can be fed into the agent at runtime.
After the agent runs, its actions become new traces for the context graph. Reinforcement learning over these traces then evaluates whether the chosen path was optimal and identifies alternative paths the agent can take in the future.
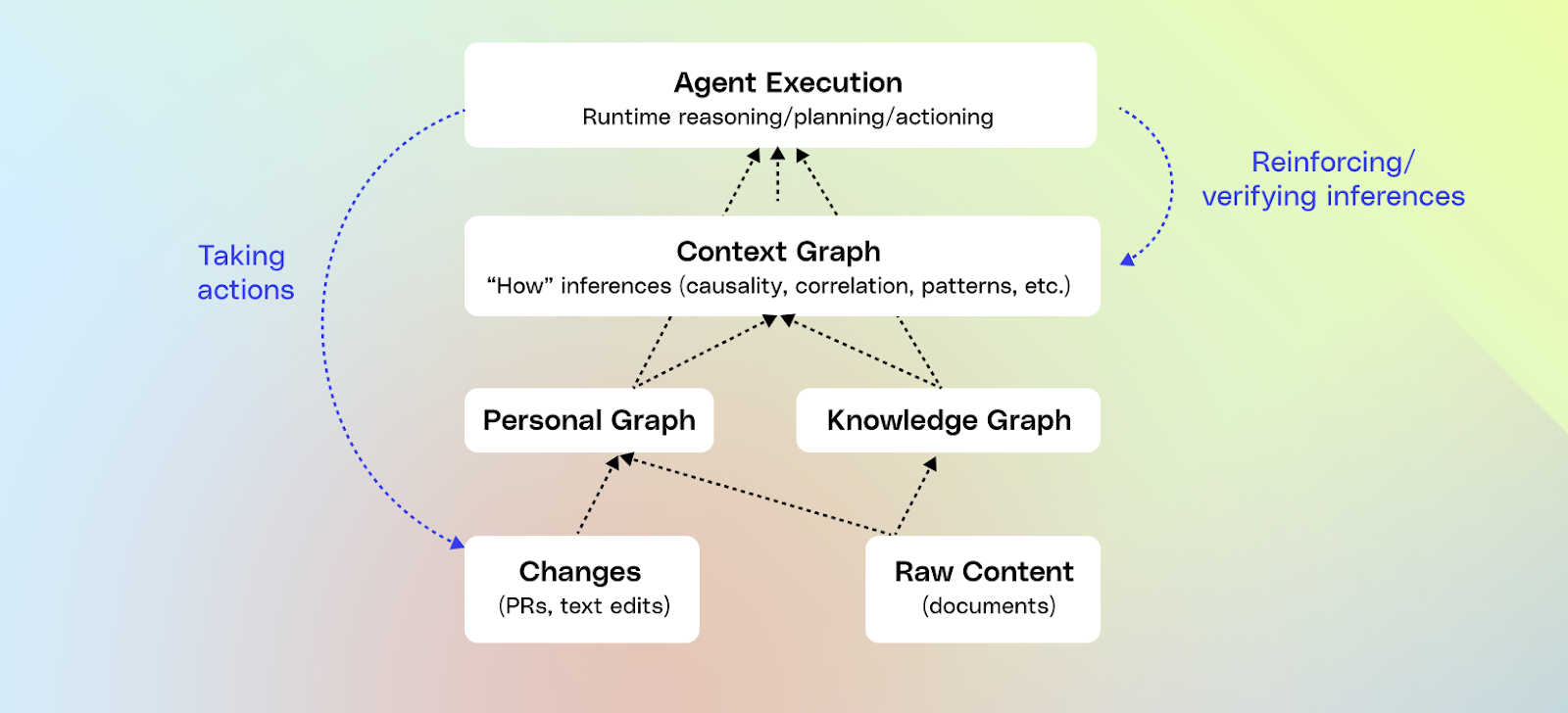
How do we build a context graph?
Investing in deep connectors and observability
Context graphs require a foundation of deep connectors and observability. If we can’t see how work happens, we can’t model it. That means integrating at a document level with the apps where work actually takes place, as well as structured data: CRM and ticketing systems, chat, docs, email, calendars, code, dashboards, and internal apps.
We understand how each app is really used—for example, Jira comments decay quickly, while the links in a Jira description are usually canonical (ie: docs, designs, etc.). We capture those patterns in a centralized data model, which we then place in our search index.
From there, the hard part is keeping that model healthy over time: chasing down inconsistent APIs, reconciling identities that differ across tools, and continually enforcing content permissions so that every result is both relevant and properly secured.
A couple of years ago, we moved towards capturing not just document data, but all of the change events in an app. We then normalize and expose them as traces, with the aim of building a context graph.
Building a unified knowledge graph
After we crawl and index data, we build a knowledge graph by running a machine learning pipeline to infer higher-level entities like projects, customers, products, teams, and people. We also identify the relationships between them—determining which docs, tickets, calls, and dashboards belong to a given product or account.
We continuously feed in activity signals (views, edits, comments, etc,) to understand how information is actually used and how people collaborate. This is how Glean understands that “ACME Inc” in CRM and “ACME” in support tickets are the same customer.
This allows us to roll up activities into the same canonical project or customer, giving a high degree of confidence as to what is actually happening.
This is why knowledge graphs are a key foundation to context graphs, because activity signals on their own are noisy, you need knowledge graphs underneath to make that activity meaningful.
Creating a personal graph
In parallel with the knowledge graph, we build a personal graph that understands your tasks and projects to offer proactive, personalized help. To build the personal graph, we collect and synthesize activity streams and traces, stitch those raw signals into timelines, and enrich them with entities from the knowledge graph:
- For each person, a chronological sequence of actions across tools, along with richer metadata.
- From there, we start grouping low-level events into semantic tasks.
That’s where it gets tricky. Real work is messy: people context switch constantly, reuse the same doc across efforts, and abandon threads and pick them back up days later. A single “edit doc” event might belong to multiple parallel streams of work.
To make sense of this, we combine:
- Simple signals like shared titles, links between tickets and docs, meeting invites, channel names, and time windows.
- LLMs that look at sequences of events and infer, “this cluster looks like investigating an alert,” or “these actions together look like drafting and socializing a spec.”
The goal is to carve the flow into coherent units of work—tasks and higher-level projects—that the system can reason about.
Now, at this point, we’ve only looked at a single individual at work. And, because we maintain user privacy, this data is only visible to them. But when we start to analyze it in aggregate, we can see themes.
Creating a context graph
When we analyze processes in aggregate, we take each personal graph and normalize it into a sequence of anonymized “steps” with coarse labels:
- action type (view, edit, comment, escalate)
- tool family (docs, chat, tickets, code)
- knowledge graph entities involved (incident type, product, service, customer segment)
- derived process tags from LLms or heuristics (e “investigate_alert”, “draft_spec”, “negotiate_contract”, “onboard_customer”)
- lightweight timing features and outcomes (e.g. “resolved P1, MTTR < 30 minutes” or “deal closed‑won”)
What we do not carry into abstracted traces is raw text (doc bodies, message text), user identifiers, or customer‑specific secrets. We then compute similarity between abstracted traces to figure out which ones are likely to involve the same process.
On top of that, we only treat a pattern as viable if it appears across at least k distinct users and n independent traces, with anything too rare dropped to preserve anonymity.
When we do this, we’re building a probabilistic view of “what tends to happen”, and “in what order,” and “why does this path deviate from other similar paths.” We then use timing to determine the value of the process. If it's taking similar groups of users a lot of time to do a process, it’s most likely a high-value process. That becomes the system’s context graph—the playbooks agents can lean on when they see a similar situation.
As we’ve built this graph, we’ve weighed different ways to store event data for traversal. Pure graph structures are rigid; raw text is flexible but hard to navigate. So we use a hybrid model: take free-form text, break it into smaller chunks, and embed entity IDs.
An incident, for example, becomes short segments that mark transitions—“investigating” to “mitigating”— by tagging them with IDs like incident_id=INC-123, channel_id=#p1-incidents, or action_type=escalated. This lets the agent walk the process step by step with clear guideposts, with the tradeoff that it’s not optimized for reasoning across thousands of incidents at once.
Learning from agentic traces
The last major step is to close the loop with agent execution. If agents run outside this system, the graph never learns from them. If they run inside it, every agent run becomes one more trace:
- Which tools it called, in what order, with what inputs and outputs.
- Whether the run completed successfully, how efficiently it ran, and whether the user downvoted or upvoted the response
All of these learnings are scoped per enterprise and focus on how the agent uses the tools, rather than storing the underlying content.
Offline, we then replay and try out alternative routes. We score the alternatives on correctness, completeness, instruction following, and efficiency. We treat these agent traces the same way we treat human ones:
- Successful runs reinforce the patterns you want the system to prefer, becoming natural language playbooks.
- Runs that need intervention highlight anti-patterns where more context or better tool use is needed
Over time, the context graph becomes a joint model of human and agent behavior. It doesn’t just describe how work used to happen; it reflects how work is unfolding now as humans and agents share more of it.
That’s why the context graph must be owned jointly by the data layer and the orchestration layer. For high-value flows—incident response, sales deals, product development—you need both: a context layer that captures a structured, process-aware model of the enterprise, and an execution layer that can plan, iterate, and generate traces. Separating them creates drift: the graph evolves one way, agent execution evolves another, and you end up with two divergent versions of reality.
Keeping the graph and orchestration in one system ensures agents stay grounded in a live, evolving model of how your enterprise actually works.

Building context graphs at Glean
Building context graphs is a big investment, and we actually tested the concept internally before building it. We manually created a context graph for Glean by relying on technology we had already built: the personal graph.
We asked employees at Glean to opt in to sharing their personal graph data, which captured what projects they worked on, the sequence of steps that they followed, and the time they spent. With the element of time, we were able to distinguish low-value from high-value processes. We then looked at which teams have the same, repeated processes that are high value, like “AE mid‑market deal cycle,” “SE proof‑of‑concept,” “on‑call incident response,” “PM feature launch,” etc.
We took the sequences of events for this work, and we validated with subject-matter experts the A-path versus the D-path to get the work done, when there are deviations, and why. We also looked at where we had blinders, or steps that we’re missing because we hadn’t crawled the right data or lacked the actions to support a given step. Then, we put resources behind making these high-value processes (vetted for both Glean and customer demand), into agents that actually work in Glean.
While these agents become a static representation of the current state, that wasn’t the end game for us. We wanted context graphs. That’s because optimal paths evolve, ownership changes, new tools show up, and more. Our goal with the context graph isn’t just to mint a static set of agents, but to keep feeding agents with fresh process insights from the graph and push more of the logic into that learned layer instead of constantly relying on manual instructions. That’s how we believe you get long-running agents that operate autonomously. And here at Glean, we’re close to making that a reality.
Looking to learn more about context graphs? Check out our previous blog here—or sign up for a free demo of Glean today.

