




最初のAIエージェントを構築し、テストでも期待どおりの結果が出たら、次に重要になるのは「評価」です。デモとして動くだけでなく、実際の業務で信頼して使えるエージェントへと進化させるためには、評価の仕組みが欠かせません。
エージェントの評価は、品質への信頼を高めるだけでなく、プラットフォームを最大限に活用するための重要なステップでもあります。そのため、すべてのビルダーが評価方法を理解することが重要です。
優れたエージェントプラットフォームは、評価を行いやすい設計になっています。例えば、指示への正確な対応、安全性、パーソナライズ、コンテキスト理解といった基本性能が担保されているため、より実務に直結する品質の向上に集中できます。
Gleanでは、検索技術で培った知見をもとに、長年にわたり大規模な評価に取り組んできました。
本ブログでは、個々のエージェントの改善方法から、企業全体で信頼性を維持するための評価の進め方までをご紹介します。
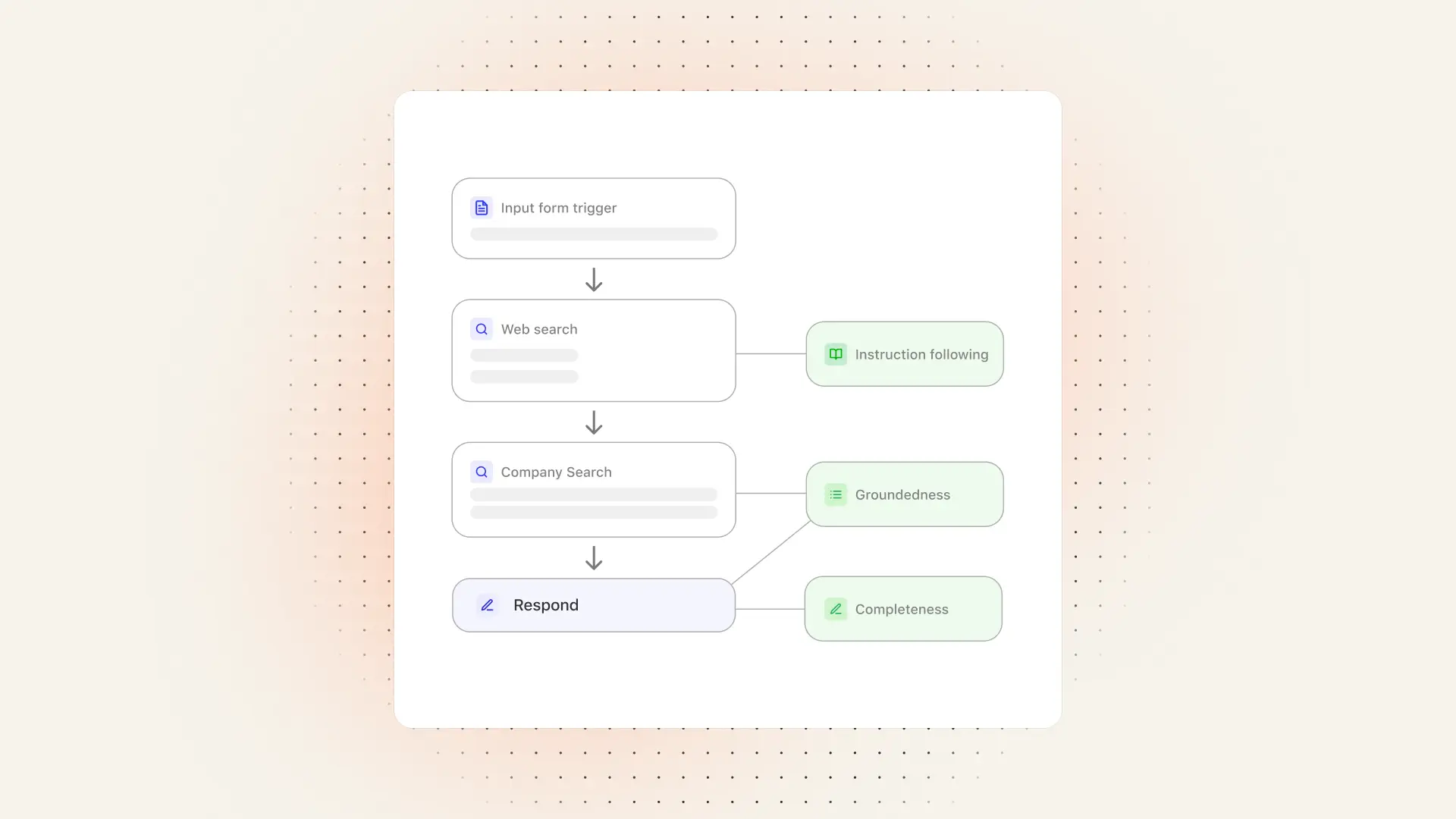
評価の設計方法
評価とは、AIエージェントが実際の業務でどれだけ成果を出しているかを、体系的に確認するための仕組みです。エージェント開発を始める前に、まずは以下のポイントを明確にしましょう。
- チームに必要なことは何か
ユーザーが日常的に行っている重要な業務を整理し、AIがどのように支援できるかを考えます。 - 成功の基準は何か
エージェントのアウトプットをどのように評価するのか、最も重要な指標(ノーススターメトリック)を定義します。
これらを事前に明確にすることで、改善につながる、シンプルで分かりやすい評価設計が可能になります。
実際の業務から始める:評価セットの作成
効果的な評価は、「評価セット」の作成から始まります。評価セットとは、実際のユーザー指示と、それに対する理想的な回答を組み合わせたものです。
最も重要なのは、実際のユーザーからデータを集めることです。
まずは現場の担当者や専門家に協力してもらい、実際の業務に基づいた約20件程度の高品質な例を集めます。
公開データや仮想的なケースだけに頼るよりも、実際の業務に即したデータの方が、はるかに価値の高い評価につながります。
また、複雑なケースも積極的に含めることが重要です。複数の情報源をまたぐタスクや、複数ステップの業務は、エージェントの価値を最大化する重要なユースケースです。
さらに、改善に入る前に、あえて難しい指示もテストすることで、エージェントの対応可能な範囲を正確に把握できます。例えば、営業支援エージェントの開発では、営業チームに「効果的な初回メールとは何か」をヒアリングし、その具体例を評価セットの基盤として活用しました。

成功の定義:指標の設計
評価セットが準備できたら、次はエージェントの成果を測る「指標」を定義します。
まずは、全員が共通認識を持てる最も重要な1つの指標(ノーススターメトリック)を設定することが重要です。
そのうえで、この主要指標を2〜4つのシンプルなサブ指標に分解し、何が良くて何を改善すべきかを明確にします。
例えば、営業向けエージェントでは「メッセージの質」を以下のように分解できます。
- 完全性:必要な情報や要素がすべて含まれているか
- パーソナライズ:相手に合わせた内容になっているか
- トーン:自然で分かりやすく、適切な表現になっているか
- 正確性(根拠):事実に基づいた内容になっているか
また、評価はシンプルに行うことが重要です。スコアは「0 or 1」のような明確な基準にすることで、判断のばらつきを防ぎ、一貫性のある評価が可能になります。
このように指標を設計することで、エージェントの改善ポイントが明確になり、継続的な品質向上につながります。
インサイトをアクションへ:エージェントの改善
評価を実施した後は、その結果をもとにエージェントを改善していくことが重要です。このフィードバックループにより、エージェントの品質を継続的に高めることができます。
まずは指標を確認し、パフォーマンスが低いポイントを特定します。次に具体的な事例を分析し、共通する課題を見つけたうえで、改善を行います。
主な改善アプローチは以下の通りです。
- 指示の最適化
より具体的な指示や良い例・悪い例を追加し、アウトプットの精度を高めます。 - コンテキストの整理
参照するデータソースを明確にし、必要な情報だけを適切に活用できるようにします。 - パラメータの調整
出力のトーンや創造性を調整し、用途に最適なバランスにします。 - モデルの見直し
タスクに応じて最適な言語モデルを選択することで、パフォーマンスを向上させます。
例えば、パーソナライズが不十分な場合は参照データを見直し、トーンに課題がある場合は具体例を追加することで改善できます。
このように評価結果をもとに的確な改善を繰り返すことで、エージェントの精度と実用性を大きく高めることができます。
大規模な評価:自動化とフィードバックの活用
エージェントの精度を高めるには、実際のユーザーによる利用とフィードバックが欠かせません。賛成・反対の評価や共有といったリアルな反応は、最も価値の高い検証データとなります。
また、実際のユーザークエリを継続的に収集し、評価セットに反映することで、変化するニーズにも対応できるようになります。
さらに、LLMを活用した自動評価を取り入れることで、ユーザー数の増加に合わせて評価プロセスを効率的に拡張できます。
Gleanでは、さまざまな業務やユースケースに対応するエージェントの品質を担保するため、大規模な自動評価を実施しています。
評価は複数の指標で構成され、ユーザーフィードバックと専門家の視点の両方を組み合わせて行われます。
このように多角的な評価を行うことで、企業全体で信頼して活用できるAIエージェントを実現します。

自信を持ってAIエージェントを構築
評価は、「動くデモ」と「実際に成果を生むAIエージェント」をつなぐ重要なステップです。実際のユーザーデータに基づいて指示や範囲を最適化することで、エージェントの精度と実用性を高めることができます。
Gleanでは、各ユースケースごとの評価に加え、プラットフォーム全体で継続的な評価を実施することで、正確性、関連性、指示遵守などの指標をモニタリングし、規模が拡大しても安定した品質を維持します。
評価を誰でも活用できる仕組みにすることで、エージェントのパフォーマンスに自信を持ち、組織全体で安心して活用できる環境を実現します。
さあ、AIエージェントの構築と評価を始め、チームの生産性をさらに高めましょう。



