




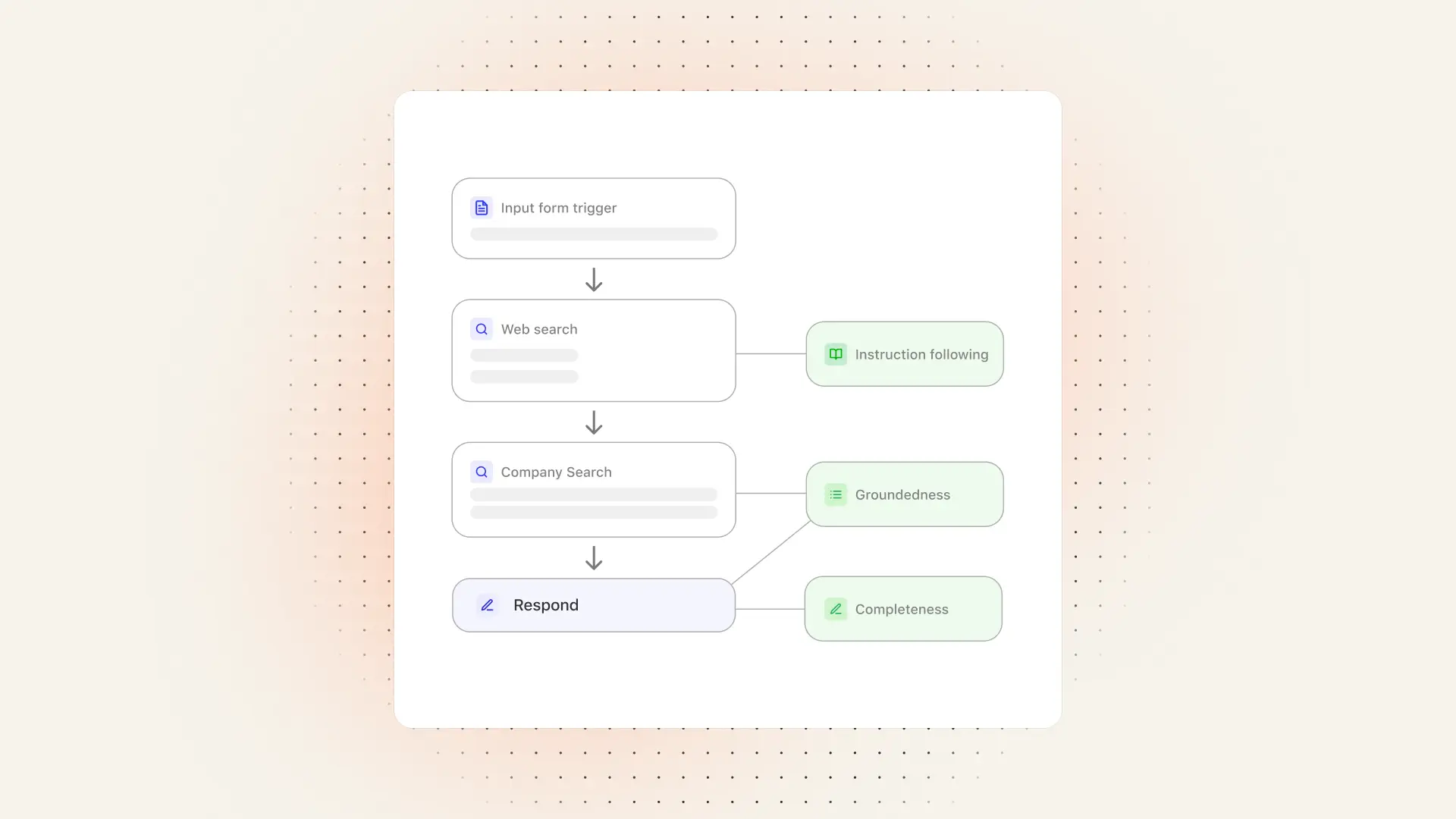
You’ve built your first agent. You run a few test queries, and the results look promising—so what’s next? The key to moving from a cool demo to a reliable agent is creating an evaluation.
Everyone should learn how to evaluate agents, not just because it builds confidence in agent quality, but because it teaches you how to best use your agent platform. The best agent platforms make evaluations accessible by assuring that agents excel at fundamentals. Think instruction-following, safety, personalization, and contextual awareness. This allows builders to focus evaluations on the higher level quality specs that make agents impactful for end users.
At Glean, we’ve been running large-scale evaluations for years, building on what we learned from search. In this blog, we’ll cover both: how you can evaluate individual agents to make them better, and how we approach evaluations at scale to keep agents reliable across the enterprise.
How to design your evaluation
Think of an evaluation as a structured way to see how your agent performs in the real world. Before you start building your agent, ask yourself a few simple questions:
- What does your team need? Picture the most important workflows your users tackle. How can an AI agent help them do their best work?
- What does a great job look like? If you had to grade the agent’s output, what would be the single most important criterion for success? This is your north star.
Answering these questions early will help you design a focused, interpretable evaluation that will provide effective guidance on how you can improve your agent.
Start with reality: Creating your evalset
A good evaluation starts with an evalset: a representative set of user instructions paired with the ideal responses. The best way to build an evalset is to go straight to the source: your users. Start by asking a few user subject matter experts to help curate a small, high-quality set of about 20 real-world examples. This is far more valuable than relying solely on public benchmarks or hypothetical queries, which often miss the complexity of your business.
Don’t shy away from complex evalsets! Users tend to push the capabilities of agents by asking for multi-step tasks across multiple sources. These aren’t edge cases, but often the most valuable jobs to be done. Start by testing instructions you’re unsure about to see exactly what your agent can handle before you dive into optimizations.
For example, when we built a sales prospecting agent, we asked the sales team what makes a great first-touch email. Their feedback and ideal examples became the core of our evalset.

What does success look like? Choosing your metrics
Once you have your evalset, you need a consistent way to grade the agent’s performance. This is where metrics come in. Start with a single north star metric, the most important measure of the agent’s quality or usefulness that everyone can align on.
Focusing on one main metric doesn’t mean ignoring how it’s achieved. Think of a great agent like a band playing in harmony: while the overall sound is the north star, each instrument needs to be in tune. Break your north star metric into 2–4 simple sub-metrics to grade consistently and get a clear picture of what to improve. For our sales prospecting agent, our north star was message quality, which we broke down into four components:
- Completeness: Does the message have all the key ingredients?
- A compelling hook to grab attention.
- A mention of the prospect's strategic priority.
- The challenge blocking that priority.
- The positive business outcome Glean delivers.
- A proof point (like a stat or customer example).
- A clear call to action.
- Personalization: Is the message tailored to the prospect?
- Relevant: “Expanding into Europe with [customer program] adds a lot of complexity—how’s your team handling knowledge sharing across time zones and regions?”
- Generic: “I see you’re rolling out AI in your app- is the next step AI for your internal teams?”
- Tone: Does the message feel personal, insightful, and easy to understand?
- Just right: “Your engineers spend just two hours a day coding—Glean helps them reclaim the rest by making code, docs, and tickets quickly discoverable.”
- Wrong tone: “Glean’s proprietary search technology queries various unstructured data sources to identify company documents relevant to each individual user.”
- Groundedness: Are the claims based on accurate enterprise and public data?
When it comes to grading metrics, simple binary scoring (0 or 1) works best. It avoids the confusion that comes with partial scores and keeps results clear and consistent. Different people often judge a “3 out of 5” differently. It also makes grading with LLM judges more reliable, since language models tend to struggle with nuanced scales. The main exceptions are metrics like cost or latency, where precise numbers really matter.
From insights to action: Improving your agent
Once you’ve run your evaluation, now it’s time for the most important part: using the results to make your agent better. You can use this feedback loop to turn a good agent into a great one.
Start by looking at the metrics to see where the agent underperformed, review examples to spot patterns, and then make targeted improvements. For example, a sales prospecting agent failing at personalization may not be using the right sources, so rewording its search instructions can help. If tone is the issue, add examples of good versus bad tone. As a rule of thumb, make agent changes in this order:
- Refine instructions: The highest-impact changes often come from refining instructions. Be more specific, add examples of what to do (and what not to do), and provide a clear framework for structuring thinking and responses.
- Structure context: Control the information the agent sees by pointing it to specific data sources when general context is too broad. You can also avoid information overload by using sub-agents with their own memory.
- Tune parameters: Adjust LLM parameters like temperature, which controls the agent’s creativity. This is a great way to fine-tune the tone of the output.
- Choose LLMs: Some models really excel at certain task domains and lag in others. Swapping the LLM for a different one may provide a significant boost.
Finding the right fix gets easier with practice. Here are a few common scenarios:
- Does your competitive insights agent give a shallow analysis? Try adding a step that directs the agent to outline its reasoning before giving the final answer.
- Does your conversational agent respond well, but too slowly? Adjust the memory settings so it only reads relevant portions of the conversation history for every response cycle.
- Does your content writing agent sound rigid and formulaic? Increase the creativity setting and give it a few snippets for inspiration.
- Does your sales messaging agent omit key customer stories? Tweak the instructions for its search steps to be more descriptive about the information it needs to find.
Evaluations at scale: Automation and closing the feedback loop
Now put your agent in your users’ hands. Real-world usage, where feedback like upvotes, downvotes, and shares help validate performance, is often the most valuable test. You can even sample real user queries and add them to your evaluation to keep your evalset fresh and aligned with evolving user needs. Alongside query sampling, automating grading using LLMs is a great way to scale your evaluations as your userbase grows.
At Glean, we run automated evaluations at scale to ensure agents for any use case and workplace are useful and trustworthy. We break down platform quality into distinct metrics. Most of these are graded by LLMs aligned to user feedback such as upvotes and downvotes, as well as human subject matter experts. By layering these metrics to cover all aspects of enterprise readiness, Glean delivers a trusted agent platform for horizontal use cases.

Start building with confidence
Evaluations are the bridge between AI agents that demo well and AI agents that drive real impact. They help you sharpen instructions, refine scope, and tune your agents based on real user data, not just guesswork.
While you evaluate agents for your specific use cases, Glean continuously runs platform-level evaluations in the background, tracking metrics like accuracy, relevance, and instruction following to ensure agents stay reliable at scale.
Our goal at Glean is to make evaluations approachable, so you can trust agent performance and feel confident sharing agents across your organization. Now, it’s your turn. Start building agents, start evaluating agents, and put an ensemble of agents to work for your team.



