






At Glean, we believe the future of AI security is AI itself. Reasoning models are becoming increasingly better at staying ahead of evolving threats by detecting attacks and sensitive data exposures.
That’s why we’re excited to share the results of our investments in AI security- new detection models that achieve 97.8% prompt injection detection, 93.5% toxic content detection, and 94.3% malicious code detection on leading benchmarks.
In this blog, we'll dig into how we arrived at these results, developed the industry's leading detection models, along with our multi-layered approach to AI security.
Multi-layered approach to AI security
By design, AI models aim to be as helpful as possible. They’ll explore multiple paths to achieve a user’s goal, even when that goal has malicious intent—unless security controls prevent it.
Many commercial and open-source models now include these AI security controls. However, in a multi-model world where models cross-collaborate on complex work, those guardrails alone are not enough. They require an additional protective layer over prompts and agents to block prompt injections, malicious code, and toxic content.
Glean’s AI security models, generally available today, provide those capabilities—taking a layered security approach to keep enterprises safe. From day one, Glean introduced permissions-enforced data connectors and access controls to prevent prompt injection attempts from causing data leakage or unauthorized actions. Now, we’re adding a new AI security layer to preserve model integrity and reliability: dedicated security models that inspect and validate chat sessions and agent execution steps.
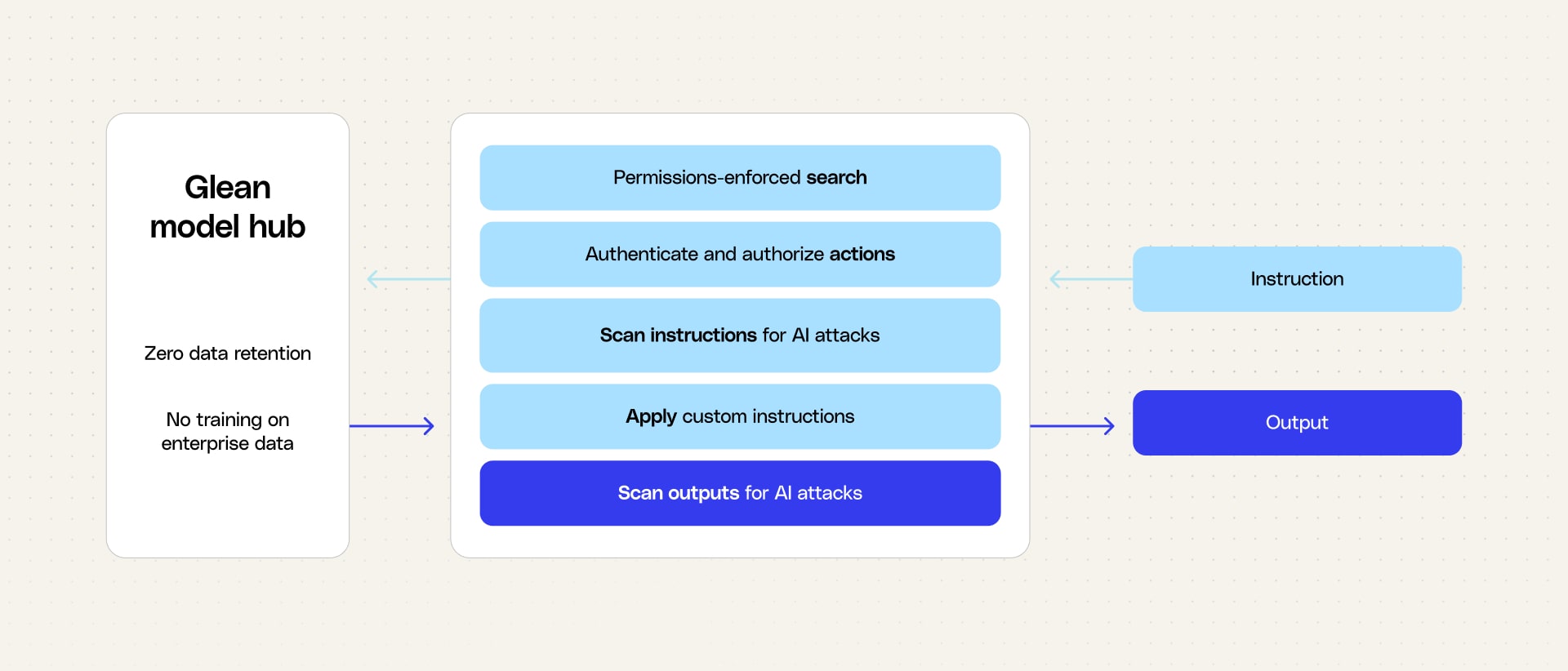
Not all AI security models are equal
Not all AI security models are equal; quality and staying current with evolving threats matter. We found out-of-the-box models don't fully protect enterprise scenarios so we developed models specifically for the enterprise AI threat landscape.
By fine-tuning using publicly available datasets relevant to enterprise scenarios, our models are better equipped to identify and mitigate enterprise-specific risks—avoiding the high false positive rates and missed threats common with generic solutions. Additionally, we employ a combination model strategy to validate initial results and further reduce false positives.
We’re sharing performance benchmarks showing how our security models stack up against leading open source LLM safety models, observability solutions, and cloud provider offerings. Glean achieves 97.8% accuracy on prompt injection detection, 93.5% accuracy on toxic content detection, and 94.3% accuracy on malicious code detection on leading benchmarks.
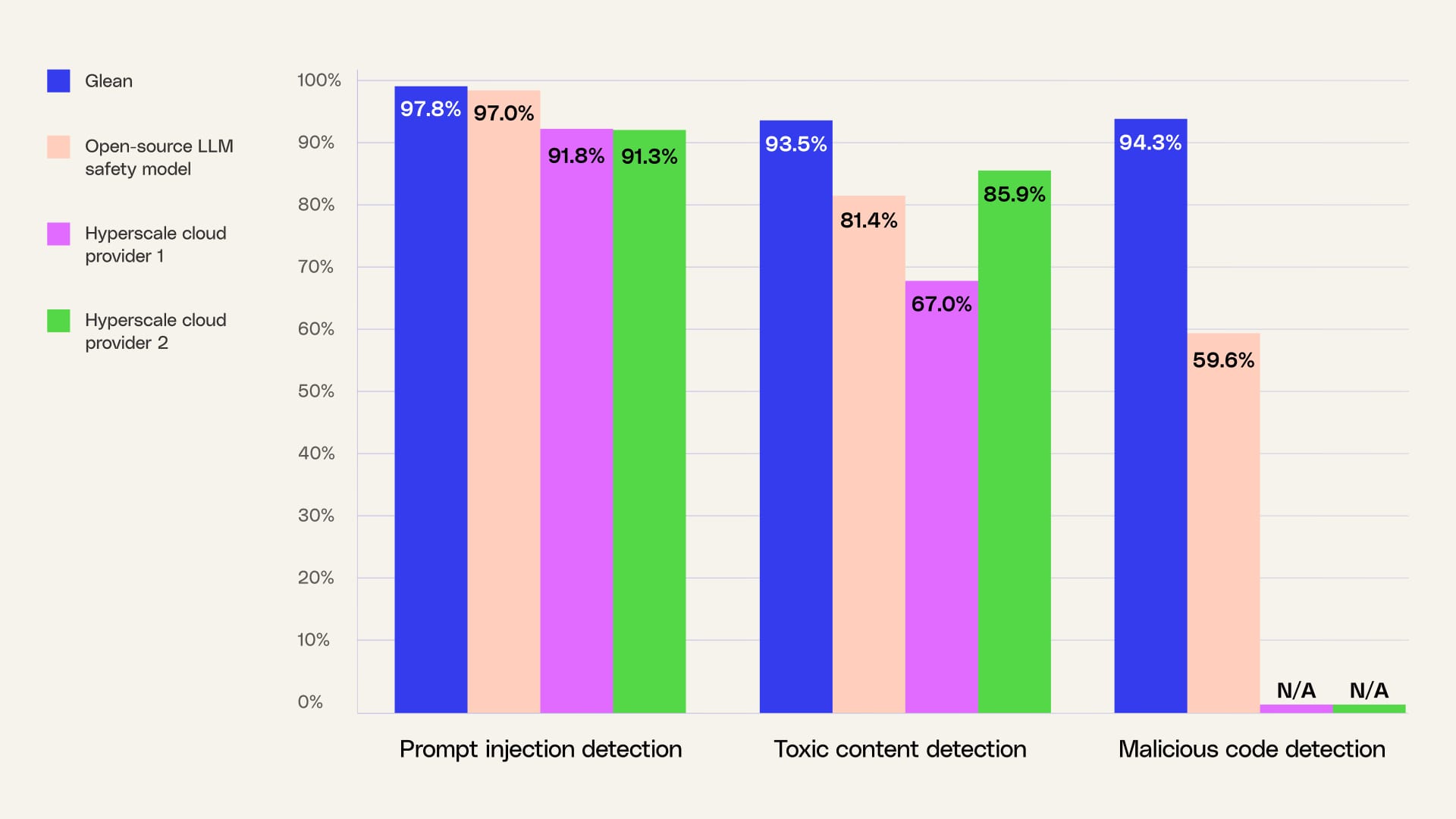

Results are averaged across the evalsets for prompt injection, toxic content, and malicious code. Hyperscale cloud providers do not support malicious code detection.
*Glean blocks direct prompt injection attacks at a 97.8% accuracy rate and indirect prompt injection attacks at a 90% accuracy rate.
*Benchmarks taken from Guardbench.
Digging deeper into the numbers, you can see that Glean sees a low false positive rate as compared to other providers. This is an important metric to zoom in on for production AI, because the user experience gets degraded if we block too many benign requests. The reason that Glean is able to achieve a low false positive rate is that we use a dual model approach to AI security, running results through a second model to ensure their accuracy.
We make it easy for users to trace the violation to the source for quick remediation with an AI security dashboard complete with the surrounding context, the prompt, source file, agent identifier, user information, and chat session.
AI security is a continued investment for Glean, today and into the future. As attacks evolve, we’ll be in the thick of it, adjusting our models to keep enterprises safe. We’re excited by today’s progress and benchmark results, and we’ll keep evolving to stay ahead and protect enterprise customers.
AI security models are part of Glean Protect+, a premium security suite. They are available today in GCP deployments.



