






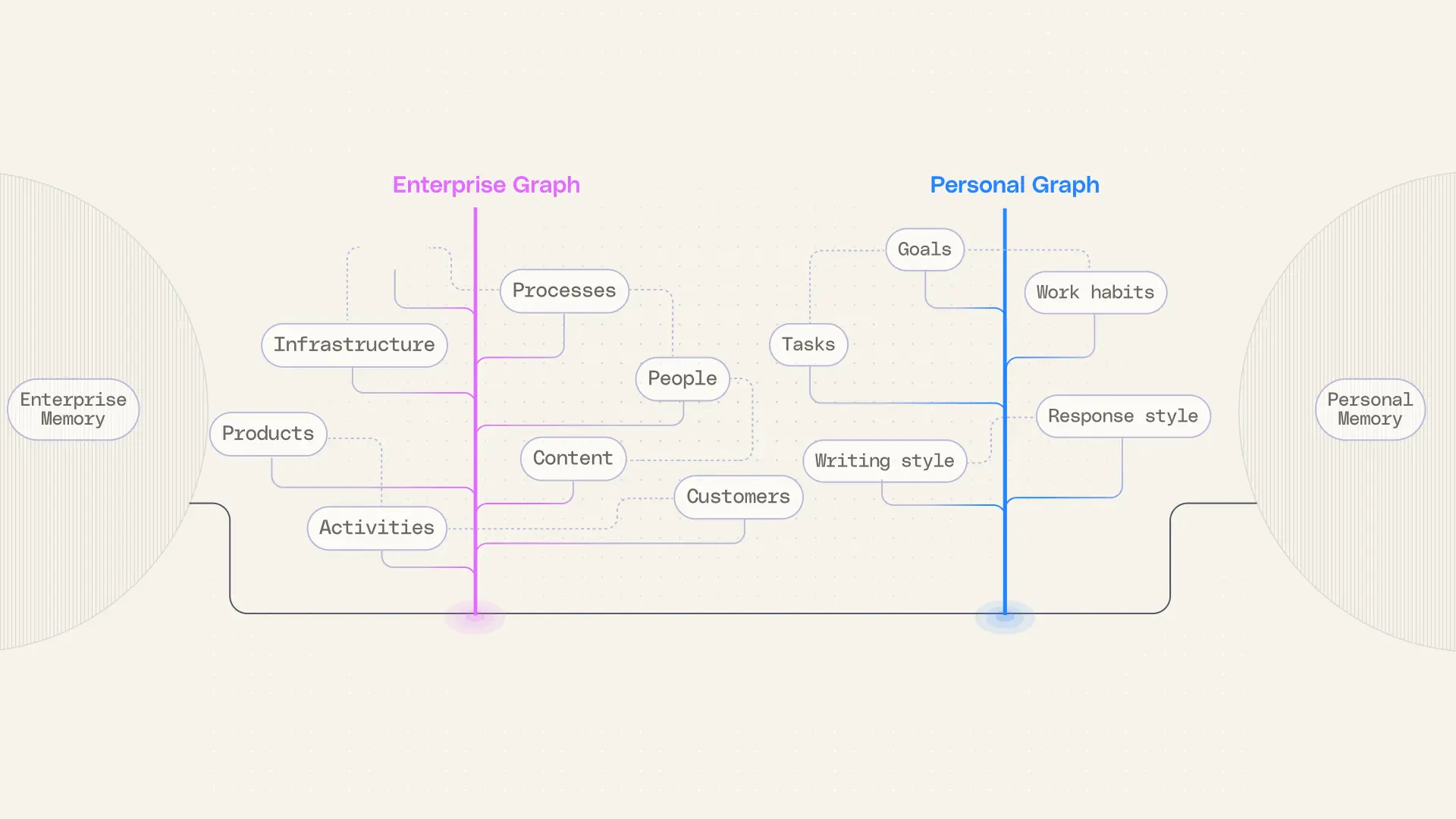
Over the past year, context engineering has become central to building capable AI agents—shaping how models interpret information and coordinate across tools to complete real work. As context windows expand and agentic workflows grow more sophisticated, the role of context has only increased. Managing it well is now foundational to whether agents succeed in the enterprise.
Frameworks like the Model Context Protocol (MCP) have accelerated this shift by making it easier to connect tools and expose functionality. In doing so, they’ve also brought the importance of context into sharper focus. Access alone doesn’t guarantee understanding, and without a unifying layer, tool availability alone can give a false sense of completeness. In practice, this often leads teams down one of two paths: hand-orchestrating MCP tools into rigid, deterministic workflows that quickly become brittle as systems evolve, or leaning on generic tool calls that inherit each system’s fragmented semantics and weak search. In both cases, the burden of managing context falls on engineers, rather than being solved at the platform layer.
Our view is that context must be a foundational capability—one that’s unified, continuously learned, and consistently delivered—so agents can operate reliably at scale. Effective agents draw on context from purpose-built systems like search, which has long understood that content alone isn’t enough. Signals such as usage, popularity, and linkage improve relevance, while graph-based structures help map relationships across people, projects, and teams. Layered with enterprise memory that learns how tools and processes fit together, this creates not just access to information, but real understanding of how work gets done.
Today, more work is shifting to AI agents. Employees are asking AI to debug engineering issues, generate informed account plans, prepare for customer meetings, and drive complex initiatives end-to-end. At the center of all of this is context. That evolution—from discovery, to understanding, to action—is what makes context the backbone of enterprise AI. In this blog, we’ll walk through our design decisions and lessons learned building enterprise context.
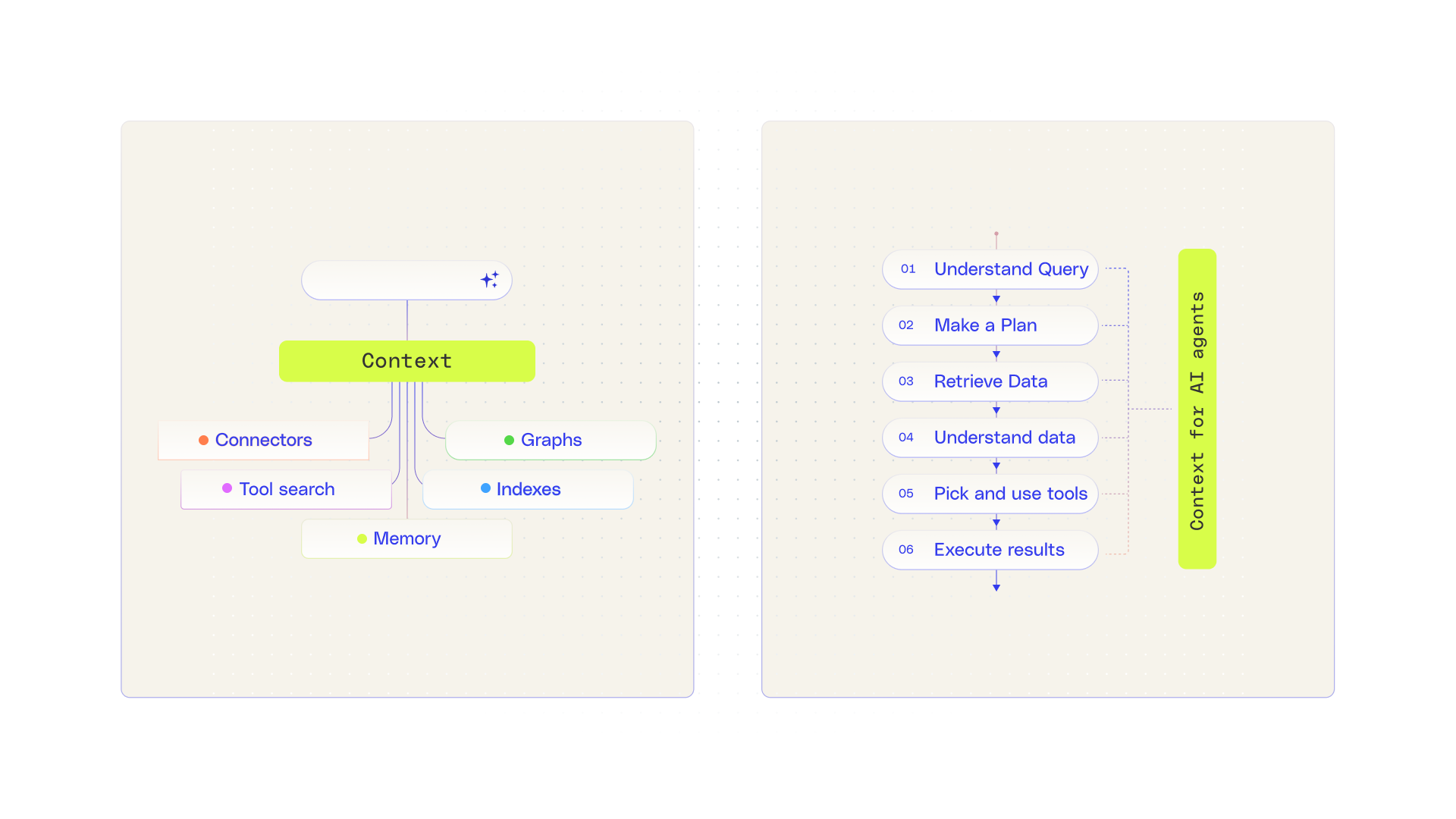
Methods to understand enterprise context
The growing adoption of MCP has also introduced some misconceptions about tool maturity and reliability. While many MCP tools provide a straightforward interface to existing APIs—which is a valuable starting point—they often lack built-in understanding of the underlying data’s semantics or how that data should be used in practice. As a result, additional context and interpretation are still required, and without a supporting platform layer, that responsibility can shift to engineers to solve.
Indexes
To reduce the cognitive load, you need to build quality tools that are flexible enough to support a wide range of use cases. What we’ve seen at Glean is that the underbelly of these tools is often indexes; indexes that shape and store the data in the best way to quickly answer a query. If you want to support a wide range of enterprise AI use cases, you’ll need different flavors of indexes for retrieval.
For example, we’ve separated out tools by the job to be done with calendar search indexing events by time and people (e.g., after:now, before:DATE, “my next meeting with John”), helping to answer questions like “when did I last meet with Judy?” or “tell me my upcoming meetings.” Whereas, Glean search is better for finding unstructured documents, tickets, and emails, especially when I need cross-application context like “what’s the latest on project falcon?” When it comes to structured data, if a user asks “What is our total ARR?”, we search an index of Salesforce dashboard data and use signals such as dashboard creator and popularity to identify the organization’s canonical metric.
Connectors and data modeling
Building centralized indexes was relatively easy when it came to internet data that’s homogenous in nature—the same cannot be said for enterprise data that’s heterogeneous. Every application has its own structure and semantics, and requires data models that capture diversity while also normalizing to return relevant results across sources. For example, in Jira, a ticket represents a specific issue, but that issue ties to a larger epic—and documents linked in the description tend to be more authoritative and long-lived than those in the comments. When you take a step back and design for the richness and understanding of enterprise data, connectors and data modeling matter a lot. It’s often the start of getting to context, but the importance is often overlooked with the rise of MCP.
There are questions as to the value of retrieval tools like enterprise search with MCP-based retrieval. At Glean, we treat MCP as complementary, combining it with our indexing system through hybrid connectors to achieve both real-time freshness and unified enterprise understanding. Like any data source, MCP tools still benefit from data modeling, signal extraction, and indexing to get value. This is context engineering that the platform should take on and it's not a one-time initiative—it has to keep up with the changes in enterprise applications (ie: new data types, new functionality, etc.).
.webp)
Knowledge graphs
Connectors and tools help surface content, but they don’t solve for relationships and canonical mappings across different applications. That’s where knowledge graphs come in. Even as model reasoning improves, graph-based structures remain the core substrate for enterprise context. By encoding entities—people, projects, and processes—and their relationships, graphs ground agents, enabling multi-hop reasoning, disambiguation of enterprise-specific language, and an understanding of how work happens.
.webp)
At its foundation, a knowledge graph represents information as linked relationships rather than isolated data points. Each relationship connects an entity to another through a defined relationship—for example, an engineer being assigned a Jira ticket or a document being linked to a project. These relationships collectively form a graph of connected entities that can be navigated to answer complex questions, uncover hidden connections, and derive insights that aren’t explicitly stored in a single source.
Models handle simple fact recall when answers are explicit or close to the source content, but they struggle with complex, multi-hop inferences especially over large context windows (“Show all codebases for projects led by X that shipped in Q1 2025”). Increasingly, enterprise agents fall into this second category—requiring multi-step reasoning across entities. This is why graphs are essential: they give agents access to complex insights to handle nuanced enterprise questions accurately.
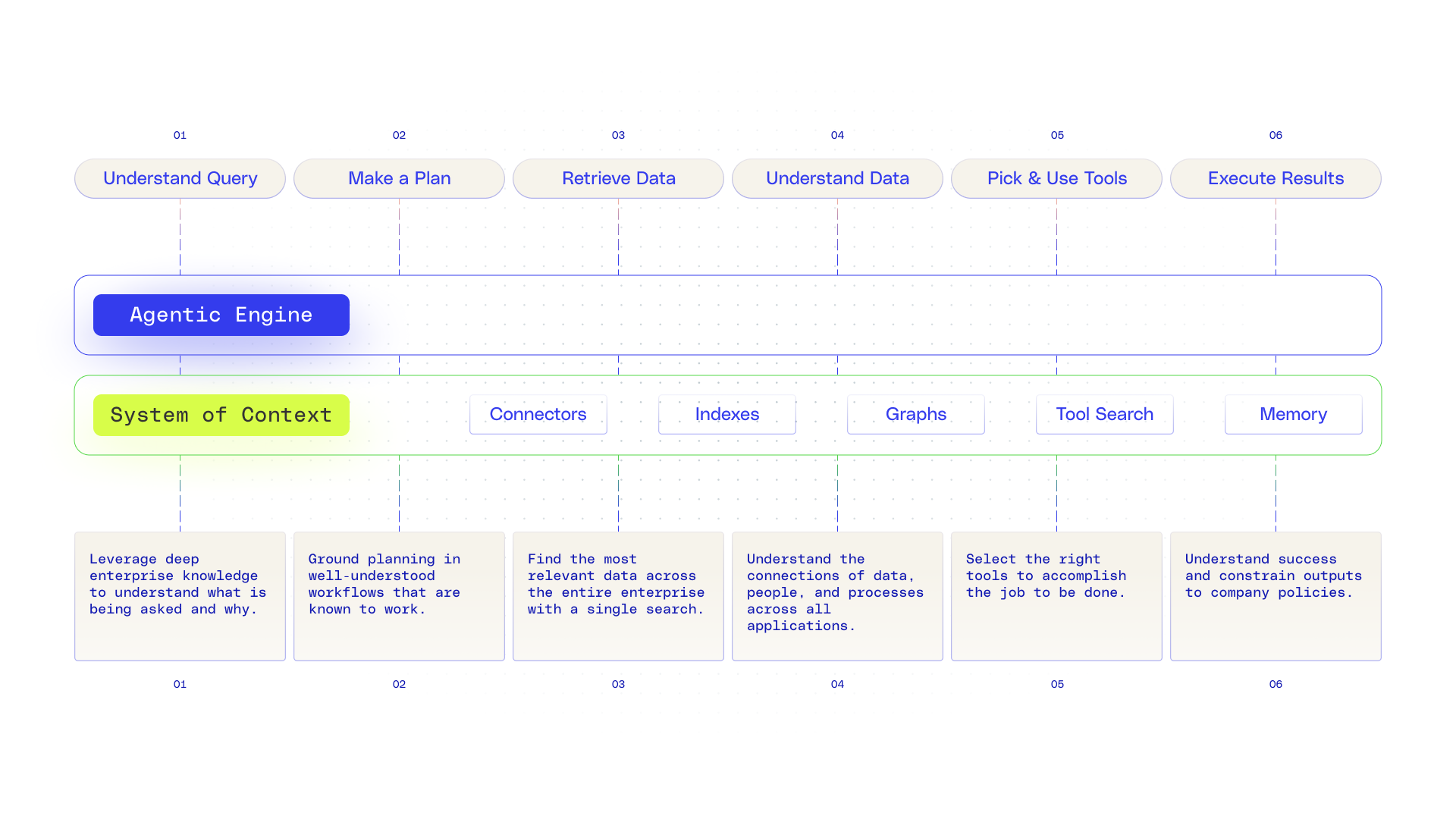
Use context to take action
We’re seeing models advance their reasoning capabilities, understanding when to iteratively plan and how to use tools, enabling AI to take on more work. Just because they know how to call tools doesn’t mean they know how to scale the use of tools in the enterprise. This is another, newly expanded space that requires optimizations and enterprise memory.
Tool search
When it comes to scaling to 100s of tools in the enterprise, the task of tool discovery and disambiguation becomes critical. This is again a search problem—creating an index of tools that can be used to find the right one or combination for the job. Glean learns which tools work best for your company by observing how your most successful agents get work done. Over time, it maps common workflows to the right tools and uses signals like popularity and data source to select the best next tool—so agents act faster without overloading the context window with unnecessary information that can lead to hallucinations.
Tool optimizations
Like many others, we’ve found that with AI agents, minimizing system prompts, giving agents a clear menu of prioritized tools, and allowing early exploration leads to higher-quality results. We’ve also focused on designing tools so they chain together easily and avoid disambiguation—by surfacing operators, streamlining inputs and outputs, and making names and descriptions clear. Tool names and descriptions evolve over time so that as tools are evaluated and new ones are added, they continue to perform optimally. We’ve also seen agents make effective use of operators, treating them as filters that guide what to look for next, which path to take, and where to go deeper. Paired with powerful retrieval tools, operators enable richer extraction and understanding of enterprise context.
Memory
While we’ve achieved incremental gains through better tool design and larger gains through tool search, these approaches still haven’t let us optimize how actions work together. This is actually a common occurrence, especially when it comes to tools that are designed for atomic actions (actions that can do one singular thing but can’t actually accomplish a task end to end) which are popular with MCP.
Consider scheduling a meeting. First, you need enterprise knowledge: who’s on the team, what’s top of mind for the agenda, how long the meeting should be- understanding how meetings are run at a company. These are retrieval tasks that rely on search tools. Then you need to actually schedule the meeting—adding email addresses, a meeting link, office space, and a time to an invite. Scheduling isn’t a single action; it’s data and actions working together in concert.
To reliably reach the goal—getting a meeting scheduled—the agent must learn which tools to use and how to parameterize them, often iterating through multiple attempts before finding the right path. But when a session ends, those hard-won insights—successful pathways, failed attempts, tool-parameter patterns—are lost instead of being systematically reused. At Glean, in an earlier version of our agentic engine, we used “workflow search” to surface similar past agents, but it didn’t update the agent’s policy for choosing or parameterizing tools—it was too coarse-grained. We replaced it with something more effective: enterprise memory.
With enterprise memory in Glean, we store traces of agent runs, including which tools were used, the parameters passed, the sequences attempted, and the outcomes. Offline, on a per-enterprise basis, we then run permutations with different tool choices and arguments. We grade the results on correctness, completeness, and efficiency, and feed the learnings back into the system in natural language—the language of LLMs. These learnings provide guidance on which tools to use and why, how to structure tool inputs, and how to sequence actions. The focus is entirely on tool-use heuristics—not on the enterprise data itself for data security protection.
.webp)
When a new, similar agentic task begins, the agent receives a targeted hint drawn from this memory—helping it choose better actions from the start. Over time, these learnings, stored at an individual enterprise level, evolve into the agentic process knowledge of your organization. The system reinforces itself: as more tasks are completed, the agent becomes increasingly skilled, ultimately reaching expert-level performance.
While scheduling a meeting is one example, we have also seen memory contribute to the following at Glean:
- Writing release notes: For Glean, release notes are spread across multiple Jira fields and typically end up as a few sentences. Memory has learned to start with the Jira issue and its links—design docs, product requirements docs, beta docs—because that’s where the authoritative details usually live, and it uses the right retrieval tools to pull that context together.
- Company metrics: It can also learn how to find company metrics—like a revenue trend—which are unique to every business. With enterprise memory, Glean learns the right data-warehouse metric for ARR instead of trying to rebuild the calculation from scratch.
- Account research: Or, take open-ended research tasks. For account research, it figures out the go-to format for the final report, helping to drive repeatable, scalable sales motions. Then, it researches, gathering intel and verifying facts along the way using memory of where your company keeps its most reliable data.
Securing context in the enterprise
When you centralize enterprise context, security has to be built into the design. There’s a misconception that federated access is inherently safer than indexing because the data isn’t copied elsewhere. In practice, security comes from multiple layers of protection, not a single design decision including permissions, least-privilege enforcement, sensitive data detection, and continuous monitoring. Federation vs. indexing is an architectural choice; the real risk posture is defined by who can see what, when, and why.
A strong context layer uses multiple, reinforcing security controls. That typically means running in the customer’s own cloud, enforcing permissions on every query, scoping or excluding sensitive sources during indexing, honoring existing sensitivity labels, and detecting overshared or high-risk content automatically. Every retrieval and action should respect source-system ACLs and enterprise policies.
As you add graphs and memory, you also introduce derived data, which needs the same rigor. If access to a source document is removed, the entities, relationships, and signals inferred from it should be removed or invalidated as well. The same rule applies to graph-based structures: users shouldn’t see derived views unless they have access to the underlying data, with the right to be forgotten semantics built in.
At Glean, we’ve made enterprise memory needs safe by design—scoped per tenant, never shared across customers, and focused on learning how work gets done (tool usage, sequences, patterns), not storing sensitive content. Taken together, the architecture that creates context is what makes AI work well—but it’s the security model around it that keeps that context safe wherever it’s used.
Context is intelligent too
There’s no single silver bullet for context engineering. It requires multiple technologies working together—intelligently—to organize information and tools so agents can reliably complete real work. Connectors are smart about what to ingest, how to interpret signals, and when to recrawl data as it changes. Search applies intelligence in how it ranks results, using relevance to surface the right information at the right time. Graphs infer relationships, algorithmically mapping connections across people, projects, documents, and systems. And memory learns over time, recognizing patterns in how work gets done, which tools are used together, and what actions lead to successful outcomes. Together, these layers transform raw data into living context that agents can understand, reason over, and act on.
When we first built Glean, we had companies coming to us to find information like “Find our social media policy” which could live in any of the hundreds of applications on the site. Now, we’re seeing that companies are asking us to not just find the policy but to “draft a social media policy for our company that conforms to industry norms, and a process for it to be approved by the right internal stakeholders.” This is an agentic task—it needs to not only know where to search for your data, but also understand company norms and the tools to get the policy approved. That’s a lot more context when it comes to agentic work.
While we’re thrilled about agent interoperability and MCP, which makes tools widely accessible, it doesn’t take the onus off an engineering team to hand-tune context. To actually free engineers from context engineering, you need a platform built for context.
Availability note: Glean enterprise memory and tool search is coming soon.



