











- High‑quality, unified enterprise context (deep connectors, specialized indexes, an Enterprise Graph, and enterprise memory) is as critical as strong models for agentic work, preventing “context rot” and outperforming approaches that rely mainly on MCP tools or shallow indexing.
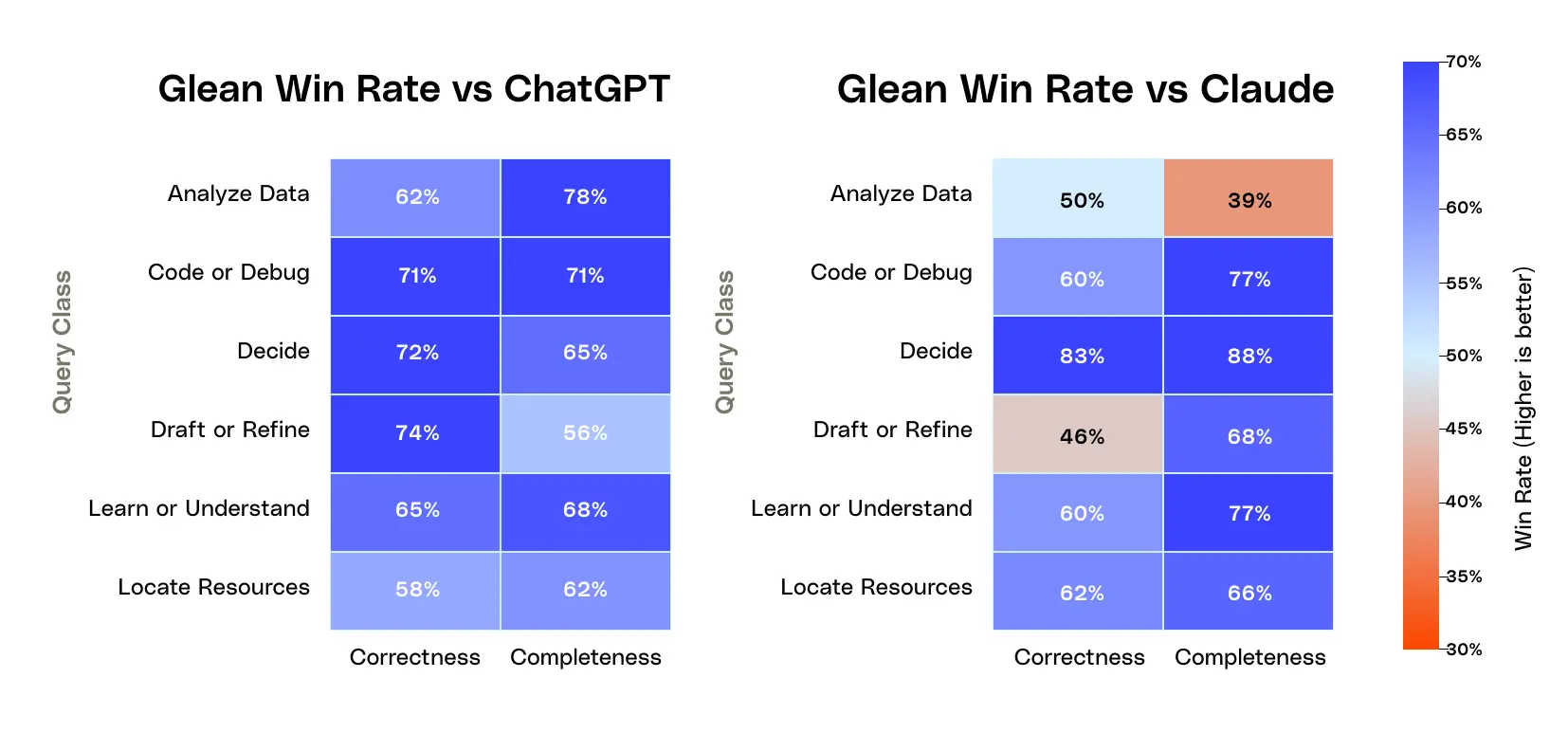
- In a blind evaluation on ~280 complex, real‑world enterprise queries over comparable data sources, human graders preferred Glean’s answers for correctness 1.9× more often than ChatGPT’s and 1.6× more often than Claude’s, and also favored Glean on completeness across all key query classes (analyze data, code/debug, decide, draft, learn, locate).
- Glean’s advantage comes from better retrieval and interpretation of enterprise data—finding canonical documents, understanding company‑specific language, resolving ambiguous queries, and surfacing concrete next steps—while ChatGPT and Claude often compensate for weaker search by over‑calling tools, which can add noise, cost, and make it harder to synthesize or course‑correct.
A year ago, when MCP took off, it looked like a simple, plug-and-play way to wire AI to data and actions, and many questioned whether the index still had staying power. A year later, the question has shifted, as the quality of off-the-shelf MCP tools didn’t deliver enterprise-grade quality: who actually has the best enterprise context layer?
It’s now widely accepted that great agents depend on high-quality context paired with strong reasoning models. You can see this across the industry: Cursor uses code search to improve answer accuracy by 12.5%. Anthropic’s context engineering guidance emphasizes that context is a critical resource for agents and must be actively curated. Even OpenAI’s company knowledge includes some synced (indexed) connectors.
So, we looked at how the stack Glean built over the last six years in enterprise context compared to new entrants in the market like OpenAI ChatGPT’s company knowledge and Anthropic Claude’s enterprise search. We discovered that human graders, when they had a preference, chose Glean's answer as correct 1.9x as often as ChatGPT's and 1.6x as often as Claude's.
The staying power of context
Before we get into the results, we want to frame why context matters for agentic work, and why models alone fall short when handling it.
LLMs have a fixed attention budget. They treat inputs as a single token sequence, with a limited sense of structure or importance. As context expands it requires the attention mechanism to spread itself across more and more tokens, weakening its ability to focus on the right ones. It also leads to interference where context starts to clash in the models memory, causing facts to blur, old and new evidence to compete, and irrelevant tokens to grab attention.
The phenomenon is called context rot. Timothy Lee, writer of newsletter Understanding AI, captured this well in a piece highlighting an Adobe study. He noted that as the “haystack” grew, model accuracy in finding the “needle” dropped sharply. And, that was just for single reasoning hops, performance dropped even further when models had to make multiple hops.
We believe at Glean that the problem with context rot is about to get a lot bigger. Agents are on the precipice of longer runs and complex work, which require a lot more context. Agents need the right context at the right stage of execution; otherwise, early retrieval errors carry forward, undermining the rest of the agent’s run.
Evaluation design
Queryset and dataset
The challenge in evaluating enterprise search is that there are no good public benchmarks. Enterprise search isn’t just about content, it’s shaped by everything around that content. Relevancy depends on signals that never show up in static datasets: how often teams open a file, who interacts with it, which systems it lives in, how it links to tickets or commits, etc. Connectors also matter: different apps expose different metadata, timestamps, and object types, and those signals heavily influence ranking and freshness. You actually have to connect real enterprise data and run real enterprise queries to be able to evaluate enterprise search.
That’s what Glean did for this evaluation. We designed our dataset and queries to mimic a real enterprise environment as closely as possible, without touching customer data. Our proxy was Glean’s own live deployment. We determined the distribution of query classes, groupings of user intent when issuing a query, across our aggregated and anonymized customer pool to preserve their privacy. We then mined ~280 queries from Glean's own internal deployment, not any customer data, that attempted to closely match that distribution, keeping in mind the limited connector profiles available in ChatGPT and Claude.
We focused the queryset on more “complex” queries, using the number of data sources the query touched as a proxy for complexity: “What’s our HR policy?” is relatively simple, because it typically relies on a single canonical document. By contrast, if a query touches multiple data sources, it may need multi-hop reasoning to reconcile entities across sources, which makes it much harder to get right.
For the dataset, we connected comparable data sources between Glean and ChatGPT, and between Glean and Claude, so that in each pairing we could test the search stack: connector depth, how the search and ranking pipelines deliver relevance, and how well the model uses search tools.
For the ChatGPT comparison, we used ChatGPT Business with company knowledge, connected to Google Drive, Google Calendar, GitHub, and Slack. For the Claude comparison, we used Claude Teams enterprise search on Sonnet 4.5, connected to Confluence, Jira, GitHub, Google Drive, Slack, and Salesforce. At the time of this evaluation, ChatGPT did not have what we consider core connectors like Jira and Salesforce, which limited how complex its queryset and dataset could be.
Since Glean is model agnostic and uses both Anthropic and OpenAI, we ran Glean on the same models. We isolated for search performance and agent harnesses by comparing Glean (GPT-5.1) versus ChatGPT, and Glean versus Claude (both on Sonnet 4.5).
Grading
We ran a blind, randomized evaluation using a five‑point preference scale (we combined preferences into categories for this blog) on the dimensions of:
- Correctness: factual accuracy and logical validity relative to the query
- Completeness: coverage of all parts of the question and necessary steps
We chose these evaluation metrics because they capture what enterprises actually care about: Is the answer trustworthy, or is it a hallucination? Did the AI fully answer the user’s query, or does the user still have to finish the job?
Citations were shown alongside responses so graders could verify factual claims. When a question fell outside their domain expertise, graders could “phone a friend” by using Glean’s expert search to find a subject‑matter expert and then confirm their judgment with them.
We chose relative grading (comparing answers against each other) rather than subjective grading, since people calibrate differently on what they consider “correct” or “complete,” and relative comparisons reduce that person‑specific bias. We also mitigated for positional bias by randomly switching the positions of Glean and ChatGPT or Claude for different queries.
We used four graders for the initial evaluation and then cross‑checked the results with our own AI quality team to ensure the grading followed the guidelines.
Evaluation results
We evaluated the results using win-loss ratios. When graders had a preference, they picked Glean over ChatGPT 1.9× more often and over Claude 1.6× more often on correctness.

Glean has solved for context by combining indexed data for fast search, Enterprise Graphs to understand relationships, and enterprise memory (via trace learning) to optimize how tools are used, focusing on the underlying data structures that power search.
When we looked at Claude and ChatGPT, we found that they tend to compensate for gaps in tool quality by issuing more tool calls. So, they’re overfetching data, which is both expensive and can pull in noise that leads to inaccurate results.
Claude and ChatGPT, however, use different tool‑calling strategies. We see Claude taking a “deep” path:
- it thinks more about the question
- issues sequential tool calls
- reads entire results in depth
- and if it’s on the wrong path, pivots and goes down a different one
Because it relies on MCP‑based tools that all have different defaults, limits, and data shapes, Claude can end up with uneven context per source. For example, if Slack returns long threads while another tool only surfaces a few short records, Slack can easily dominate the context window and skew what the model pays attention to. In addition, we found that it was difficult for Claude to course correct once it went down a particular path. For instance, once it determined that Slack could answer the question, it often did not invoke other MCP tools to find the canonical source.
ChatGPT, in comparison, takes a “wide” strategy by issuing searches in parallel and only looking at the most relevant snippets from each document. It optimizes for speed and breadth by first skimming documents, firing off many searches and touching many documents, and then diving deep into a few of the documents that are most relevant. Despite OpenAI’s best efforts to probe wide and deep, sometimes it still fails to find the relevant information due to the quality of the underlying search tools. The other challenge with this approach is that it can lead to context overload, as OpenAI reads documents from many sources, and has a hard time synthesizing conflicting data, including older documents with newer ones.
While we didn’t measure latency or cost, every tool call is an expense. Relying on many tool calls and tokens to comb through largely irrelevant data becomes a costly workaround and can also hit rate limits, causing future queries to fail for other users in the organization. Indexes and knowledge graphs continue to persist because they’re highly accurate and avoid the classic trap of brute-forcing with compute.
Query classes
We then dug into how Glean performed across different query classes. While search is often treated as a single category, in practice it underpins many kinds of agentic work, including:
- Analyzing data: Calculating metrics, finding patterns, generating charts and tables
- Coding and debugging: Writing code or troubleshooting technical configurations
- Making decisions: Weighing options, comparing trade‑offs, recommending a course of action
- Drafting content: Writing or editing emails, docs, specs, and presentations
- Learning: Explaining, defining, and providing step‑by‑step walkthroughs
- Finding information: Classic search—locating a specific document or resource
When we look at the distribution of queries where Glean was preferred, the wins are spread across these categories, reflecting the different ways enterprises actually use AI today.
The quantitative results only tell part of the story, so we also dug into a qualitative assessment of where and why Glean, ChatGPT, and Claude each performed better.
Correctness
Wins
Glean was better at finding the canonical document, understanding company‑specific jargon, handling ambiguous queries, and answering technical queries.
On correctness, Glean performed better on tasks that needed the authoritative source for an answer. That reflects our roots in enterprise search, where accuracy depends on retrieving the right document, and then the right snippet.
Under the hood, Glean builds a semantic search model for each enterprise, stored securely in the customer’s VPC. The model learns the company’s language and becomes attuned to products, customers, projects, abbreviations and industry terms. The semantic models were part of why Glean outperformed on queries that relied on company‑specific jargon.
Glean also maintains an Enterprise Graph over data, mapping relationships between projects, customers, teams, tickets, docs, and code. When a query is ambiguous, Glean can leverage this graph to find the project or entity intended by the user.
Glean’s search foundations also go beyond a single index: we build multiple specialized indexes over your data, tuned to the query type. For example, we maintain dedicated lexical and semantic indexes for code search, which helps us perform better on technical queries where the relevant context lives in code rather than documents.

I'll search Salesforce for accounts assigned to Martinique. Martinique Charleston is assigned to 43 accounts in Salesforce as the Customer Success Manager. Here's the complete list:
Accounts (A-Z)
- Adler Street Capital
- Aether Ridge Energy
- AlioraCorp
- Antivex Systems
- Apexion Materials
- Aurora Global Logistics
- Brookline Inc.
- CashTrail Rewards
- Cepora
- ChromaWave
- CloudBridge Nexus (Partner)
- CodeFountain Labs
- Cyphin Labs
- Diamond Analytics
- Diatris Foundation
- DualSight Metrics
- Elora
- Exonaa Financial
- Fork Analytics
- Fortisense Labs
- Granite Edge Management
- Harborline Capital Group
- Harmony Capital
- Hyperine
- Intellibug Labs
- Keystone Balance Advisors, LLC
- LoopTransit Labs
- Lumina Vector AG
- Northwind Strategy Group
- NovaCredi México
- Onyx Harbor Security
- Pathwise Learning Institute
- PulseLink Safety Systems
- SeatPilot Systems
- Sparklift Intelligence
- Starlight Arcade Studios
- Stonegate Payments
- Summit Ridge Ventures
- TreeLine Field Systems
- VectorSignal Insights
- Wavecrest IT Services
Would you like to see more details about any specific accounts or filter this list by industry, size, or other criteria?
I'll search Salesforce to find accounts assigned to Martinique. Martinique Charleston is assigned to one account in Salesforce: Neptune
Account Details:
- Account Name: Neptune
- Account ID: XXXX
- Owner: Martinique Charleston
- Industry: Internet Software & Services
- Type: Open Opportunity Prospect
Note: This information is based on current Salesforce data where Martinique Charleston is listed as the account owner.
Glean inferred that Martinique is a customer success manager and read owner as the CSM assigned to the account, rather than the account owner. Claude only retrieved a single record listing Martinique as the account owner. Glean is able to better infer the user intent from the query given its depth of indexing, pulling in richer more structured fields, and the Enterprise Graph that maps employees, like Martinique, to accounts.
I'll search for information about corpus stats frequency in your company's documentation. Based on the search results, corpus stats runs at multiple frequencies depending on the pipeline variant:
Main Corpus Stats Pipeline
corpus_stats runs on a dual schedule:
-
Daily: Midnight UTC
(
0 0 * * *) -
Hourly: Every hour from 1–23 UTC
(
0 1-23 * * *), only if the last fresh dump is less than 65 minutes old
The hourly runs trigger only for fresh dumps with a maximum age of 65 minutes, while the daily run executes regardless of dump freshness to ensure coverage.
Corpus Stats DAC Only
corpus_stats_dac_only runs
weekly on Sundays at midnight UTC
(0 0 * * 0).
This variant specifically calculates document X counts with a Y lookback period.
Related Pipeline
corpus_insights runs on a different schedule - twice monthly — on the 1st and 16th at midnight UTC, with consecutive runs 15 days apart
You can view the current pipeline execution schedules and job runs at go/xxx. Need help understanding why a specific corpus stats run failed or adjusting the frequency?
I'll search for information about corpus stats and their frequency in your company systems. Based on my search through internal communications and documentation, corpus stats runs on a weekly cadence.
The corpus_stats pipeline depends on docs_data completion and runs approximately once per week. When examining the X files generated by the pipeline, the dates show a consistent weekly pattern (October 4, October 11, October 18, November 4).
There's also a variant called corpus_stats_xxx_only that runs on the same weekly schedule.
It's worth noting that the pipeline has a threshold check - it won't run if the most recent docs_data is not fresh enough. The threshold is approximately 1 hour and 5 minutes.
Glean correctly identified the tiered schedule for running corpus stats, whereas Claude incorrectly inferred a single weekly cadence. Glean didn’t have to rely only on documents that might be out of date or inaccurate—it could also look directly at the code as the source of truth. By contrast, Claude search leaned heavily on Slack.
Losses
That said, there were areas where others did better than Glean. One was knowing when to ask for clarification: Claude often recognized when there wasn’t enough direction or data to answer and chose to ask follow-up questions instead.
ChatGPT tended to be better at following explicit user instructions tied to a particular data source or procedure, narrowing in on exactly what was requested. Glean, by contrast, optimizes for usefulness. When we see missing context or opportunities to add helpful detail, we’ll sometimes go beyond the literal wording of the query to fill in gaps, while still grounding everything in your company’s knowledge.
Completeness
Wins
On completeness, we saw Glean outperform on queries that required comprehensive technical details, actionable next steps, and an understanding of comprehensive frameworks.
When we looked at the graders’ comments, they preferred responses that spelled out the concrete steps and included the right Slack channels, intake forms, Jira tickets, or playbooks. Part of this comes from the Enterprise Graph and knowing how Jira tickets relate to different projects, but it also comes from recognizing the user's intent in the enterprise context and answering questions more holistically by surfacing concrete next steps.
Glean is also better at staying focused on user intent because it retrieves more relevant context for the user’s query. When that context is rich, specific, and on‑target, the model can infer “what this is really about” from the surrounding evidence instead of relying on the query alone. In other words, better context lets the agent infer intent rather than guess at it.
When the task is to create a coherent framework (competitive teardown, decision framework, multi‑step plan), Glean’s advantage is that it can reliably see more of the relevant landscape and structure it with the Enterprise Graph. So, the AI can systematically traverse related material instead of over‑weighting the results from a single source.
From the docs tied to Juniper Beta, the project is managed primarily by:
- Product management / overall beta program: Arvin Allworth (Product Manager, Growth & Knowledge Management). He’s the PM on Juniper, owning docs like “Juniper - Weekly Update” and “Juniper Beta Candidate Apps”, which describe and track the beta.
- Engineering leadership for Juniper: Sam Aimes (Software Engineer, EM for the Juniper team). He appears as manager for the core Juniper engineers and is listed as an owner on “Proactive intelligence (Juniper)”.
- Day-to-day beta rollout / experiment config: Bradley Murphey (Software Engineer). is the primary IC editing and owning configs like “[Juniper] Draft of experiment config to greenlist Juniper BETA users” and “Juniper beta: add Crema Inc. and Popsicle Io testers to home_page_task_list_greenlist”, which are specifically about the beta cohort and rollout mechanics.
So: Arvin is managing the Juniper Beta program on the product side, with Sam leading the engineering team and Bradley driving the beta experiment configuration and rollout work.
Would you like their contact info or the specific doc names referenced?
The Juniper beta is being led by Arvin Allworth — he’s the PM/DRI for Project Juniper (announced in Slack and listed as PM in the R&D execution doc).
Glean provided a more complete response by listing all of the project leaders, whereas ChatGPT only mentioned the overall PM. Glean’s Enterprise Graph can identify the different types of project owners and understand what people are working on across the organization.
Losses
We found that ChatGPT tends to win on completeness when a query benefits from multiple approaches or examples like by showing 3 different ways, comparing patterns, and giving alternatives in different coding languages.
We also saw a consistent bias toward causal explanations with expanded context. ChatGPT likes to present a complete narrative in a step-by-step fashion and to elaborate with analogies or examples, which makes answers feel more fully explained. Glean, by contrast, is optimized to be more concise and task‑oriented, with less narrative build‑up. In side‑by‑side comparisons, that pragmatism can sometimes appear to be insufficient context next to ChatGPT’s more expansive style.
As Glean continues to personalize the experience, we’re moving away from global preferences and becoming more adaptable to the individual. If a user prefers a more direct, singular response, Glean memory will adapt as we learn from user interactions and personal preferences. Completeness is ultimately in the eye of the user, and our goal is to make sure they get all the information they want the way they want it.
Not all context is created equal
To deliver quality enterprise context requires the right technical foundations. That’s what we’ve been investing in at Glean: connectors, indexes, Enterprise Graph, enterprise memory (via trace learning), and skills working together to give agents the context they need to operate fully and accurately.
As the size and diversity of enterprise data used by AI grows, those foundations matter even more. Most new entrants still support only a handful of integrations, far from representative of the apps inside a modern enterprise, and then fill the coverage gap via MCP. Naive MCP implementations introduce challenges around how tools are called, often exposing tools with weak or inconsistent quality, making it difficult to reconcile and blend results across tools.
Glean has 100+ connectors, and that matters. We can take on more agentic work because we see more of the enterprise and because the context stack beneath it is built to handle that scale. And through the remote Glean MCP server, we make that unified context available wherever you choose to use AI, so you can bring Glean context into ChatGPT or Claude too. We’re continuing to enhance how Glean shows up in both, with the goal of making full enterprise context the backbone of your work in ChatGPT and Claude.
Authors: Matthew Zhao, Karthik Rajkumar, Neil Dhruva, Julie Mills, Matt Ding, Anshul Negi



