





.png)
企業内で確実に行動を起こせるエージェントを構築するには、人間が情報をどのように理解しているかを反映したシステムが必要です。つまり、人間が読み取った情報を周囲の人々、プロセス、ツール、プロジェクト、戦略に結び付けることです。こうした連想は、人間にとっては当然のことであり、複雑な情報や矛盾する情報を解き明かして意思決定を行う方法です。LLMが同じことを行うには、人間のように推論するだけでなく、人間のように知識を使う必要があります。だからこそ、優れたエージェントエンジンの基盤は、モデルに適切なコンテキストを提供するナレッジグラフです。
Glean では、ナレッジグラフを新しいレイヤー、つまりパーソナルグラフで拡張しました。これにより、職場での人間のコンテキストをよりよく理解できます。さまざまなタイプの仕事へのアプローチを理解し、AIを適切に調整することで、チャット履歴を超えたパーソナライゼーションが必要です。これらのグラフとGleanのハイブリッド検索アーキテクチャを組み合わせると、 コンテキストシステム: 各組織がどのように機能しているかを反映して、AIが組織内の全員にとってより良く機能するようにしています。
ナレッジグラフとは?
ナレッジグラフは、エンティティとエンティティ間の関係を機械可読形式でキャプチャした情報を構造化して表現したものです。企業環境では、ナレッジグラフは、人、文書、ツール、プロジェクト、システムにまたがる断片化されたデータをまとまりのあるネットワークに結び付ける基本的な抽象化レイヤーの役割を果たします。検索インデックスとは異なり、ナレッジグラフはコンテンツだけでなく、顧客間やサポートチケット間の関係などの関係にも焦点を当てているため、企業のAIシステムをコンテキスト知識に根付かせるのに非常に適しています。
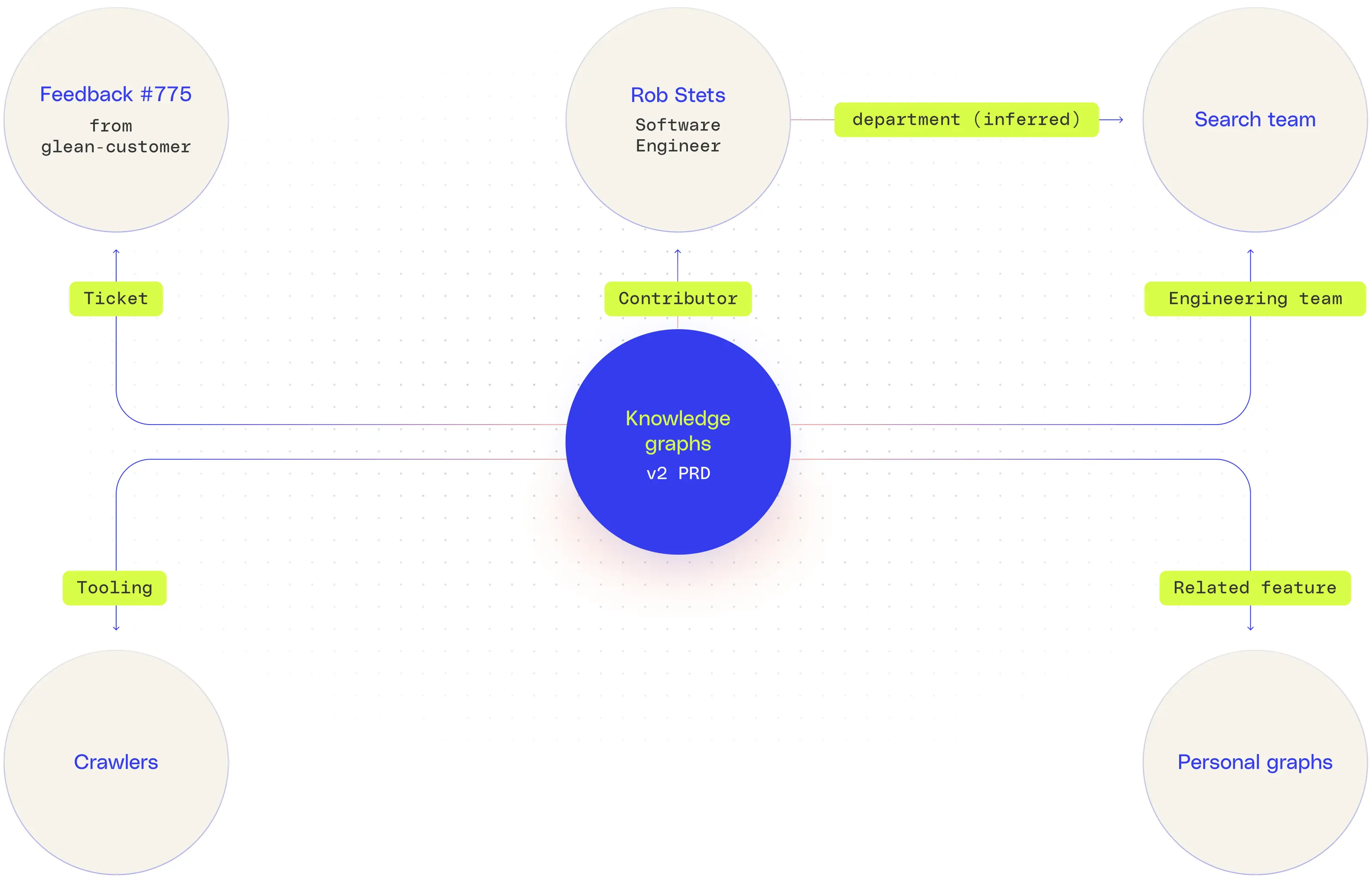
ナレッジグラフの中核となるのは、トリプレット構造 (主語、述語、オブジェクト) です。これにより、(エンジニア A、所有者、Jira チケット B) や (文書 X、参考文献、プロジェクト Y) などの特定の事実または関係がエンコードされます。これらのセマンティック・トリプルはグラフの端を形成し、それを調べて追加の知識を推測したり、複雑なクエリを解決したりすることができます。エンタープライズシナリオでは、これにより、製品リリースがロードマップ文書、寄稿者、サポートケース、顧客フィードバックとどのように関連しているかを特定するなど、組織のサイロ全体にわたる微妙な洞察が浮き彫りになります。
ナレッジグラフの表現力には、関係性に加えてその他の事実も含まれます。タイムスタンプ、アクセス制御、信頼度スコア、出自などのエッジプロパティを各関係に添付できるため、システムはエンタープライズガバナンスに不可欠なメタデータを使用して推論できます。たとえば、グラフはそれを表すだけでなく (従業員 A、報告先、マネージャー B)、報告関係がいつ始まったか、または情報がカレンダー、ディレクトリ、または電子メールスレッドから推測されたかどうかを追跡することもできます。Glean のグラフ全体はきめ細かなアクセス制御で設計されているため、従業員はソースシステムですでに共有されているデータのみを見ることができます。
実際には、エンタープライズナレッジグラフを使用すると、データサイロを横断して情報を取得でき、セマンティック検索によく見られる幻覚を回避できます。これらはコンテクスチュアル・インテリジェンスの結合組織として機能し、AIエージェントとアシスタントがデータの関係を理解できるようにします。
ナレッジグラフの仕組み
企業でのナレッジグラフの作成は、自然言語入力から意味のあるエンティティを抽出して特定することから始まります。「Reddit」という言葉を例にとってみましょう。一見シンプルに見えるかもしれませんが、「Reddit」は文脈によってまったく異なるエンティティを指すことがあります。営業組織のアカウントマネージャーが言及した場合、それはおそらく顧客を指します。マーケティングの会話では、ソーシャルメディアサイト「Reddit」での広告費を指しているかもしれません。これらの意味を明確にするには、ナレッジグラフ内のエンティティを正しく識別してマッピングするために、ユーザーの役割、意図、および周囲のコンテンツを考慮したコンテキスト対応のアノテーションが必要です。
エンティティに注釈を付けたら、次のステップはクエリの背後にある意図を理解することです。これには、自然言語クエリをプログラムで実行できる構造化された表現に変換することが含まれます。従来、これは半自動学習によって達成されていました。人間のオペレーターは、「Find Jira label」などの既知のクエリパターンをシードし、それらを使用して共通の意図を特定します。次に、これらのシードクエリをクエリログを分析して拡張し、同じ目的に一致する他のフレーズを見つけます。このプロセスは大規模なパターンマッチングに似ています。パターンマッチングでは、言語で繰り返される構造に基づいて意図が既知のエンティティやクエリタイプにリンクされます。
第 3 フェーズでは、構造化されたインテントを取得し、適切なアクションを実行します。多くの場合、ナレッジグラフにクエリを実行します。たとえば、「Reddit で使用されている Jira ラベルを検索する」などの構造化クエリを実行して、関連情報を取得できます。この履行ステップでは、グラフ構造が不可欠であることが証明されます。これにより、システムはグラフ内のエンティティ間の関係をトラバースすることで正確な情報を取得できます。
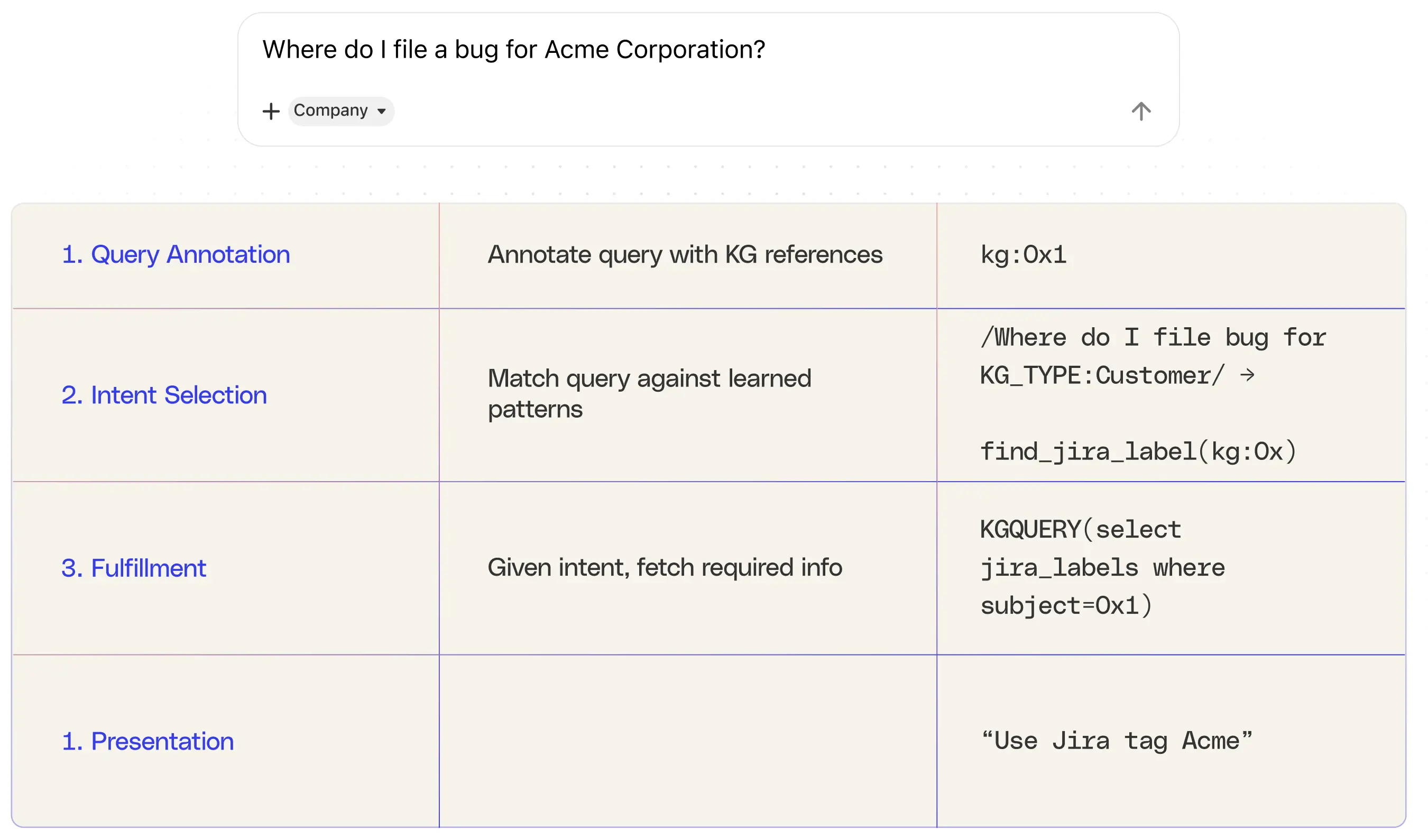
LLM の導入により、最初の 2 つのフェーズ (エンティティの注釈と意図の認識) が大幅に強化され、自動化されました。LLMは自然言語の解析に優れているため、手作業によるパターン作成やルールベースの曖昧性解消の必要性が減ります。
Glean では、LLMの助けを借りて数千のエッジをサポートするようにグラフを拡張しました。LLMを使っても、ナレッジグラフは簡単に作成できるものではありません。それについては後で詳しく説明します。
LLMがエンタープライズAIのユースケースで不十分なところ
LLMは、コンテキストウィンドウ内で幅広い意味的関連性を捉えるのに効果的ですが、マルチホップ推論、企業固有の言語、プロセスや使用パターンの理解には苦労します。その結果、LLMベースのデータ抽出は本質的に損失を伴う傾向があります。
LLM自身は、正確な事実の想起や、「Project Xに貢献したのは誰か」という回答など、列挙が必要なタスクに苦労しています。または「顧客 ABC のすべての Jira ラベルを一覧表示」さらに、LLMは自然言語を誤って解釈したり、ユーザーの意図を誤って分類したりする可能性があります。これは、NLPの失敗に根ざした問題です。そこで役立つのがナレッジグラフです。構造化されたリレーションシップと検証済みのエンティティに基づいて回答を行うことで、曖昧さを軽減し、信頼性を高めることができます。
LLM(オーバー)は条件の近さを重視します
企業環境では、LLMは正確性に苦労することが多く、条件の近さを上回ります。たとえば、架空のユーザー、フィールドマーケティングマネージャーのジェニファーアームストロングを考えてみましょう。最近の質問では、Jenniferがカスタマーサプライヤーおよび従業員エクスペリエンスの責任者として誤って特定されました。問題をさかのぼると、LLMは彼女が主催したイベントに関するSlackメッセージを誤って解釈し、彼女に間違ったタイトルを割り当てていました。
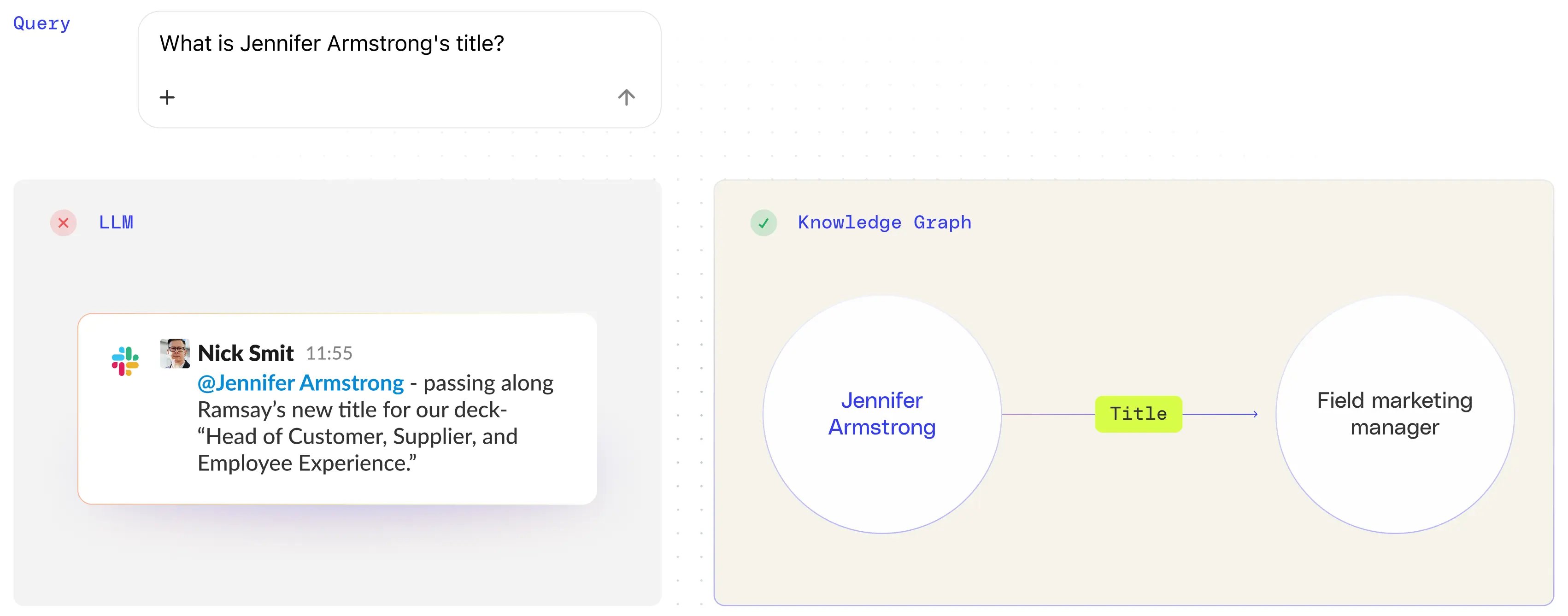
LLMは似たような名前のエンティティを混同します
製品の命名にも同様の問題が発生します。Claude 3.7 SonnetとClaude 3.5 Sonnet v2は異なるモデルですが、LLMではこの2つを混同して、機能やドキュメントを1つの間違った答えにまとめることがよくあります。構造的な曖昧さがないと、モデルバージョン間の微妙な違いでも誤って表現されやすくなります。
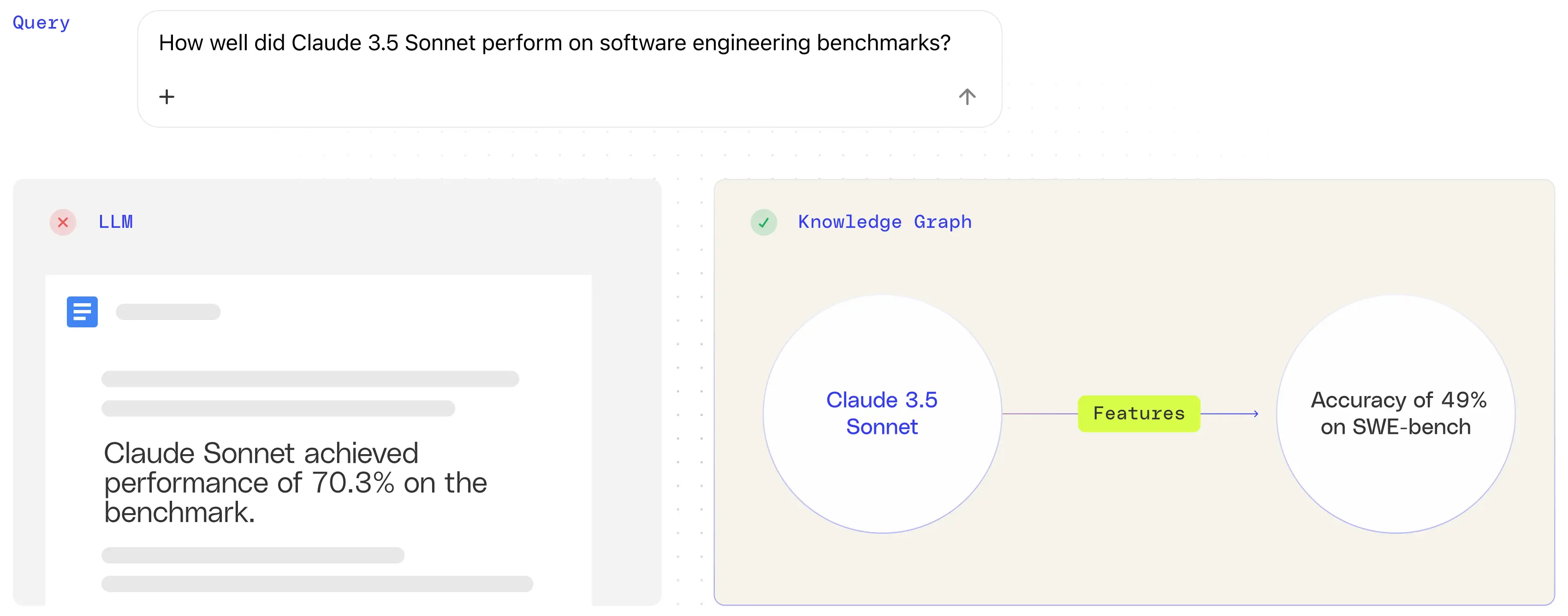
LLMは決定論的クエリに苦戦している
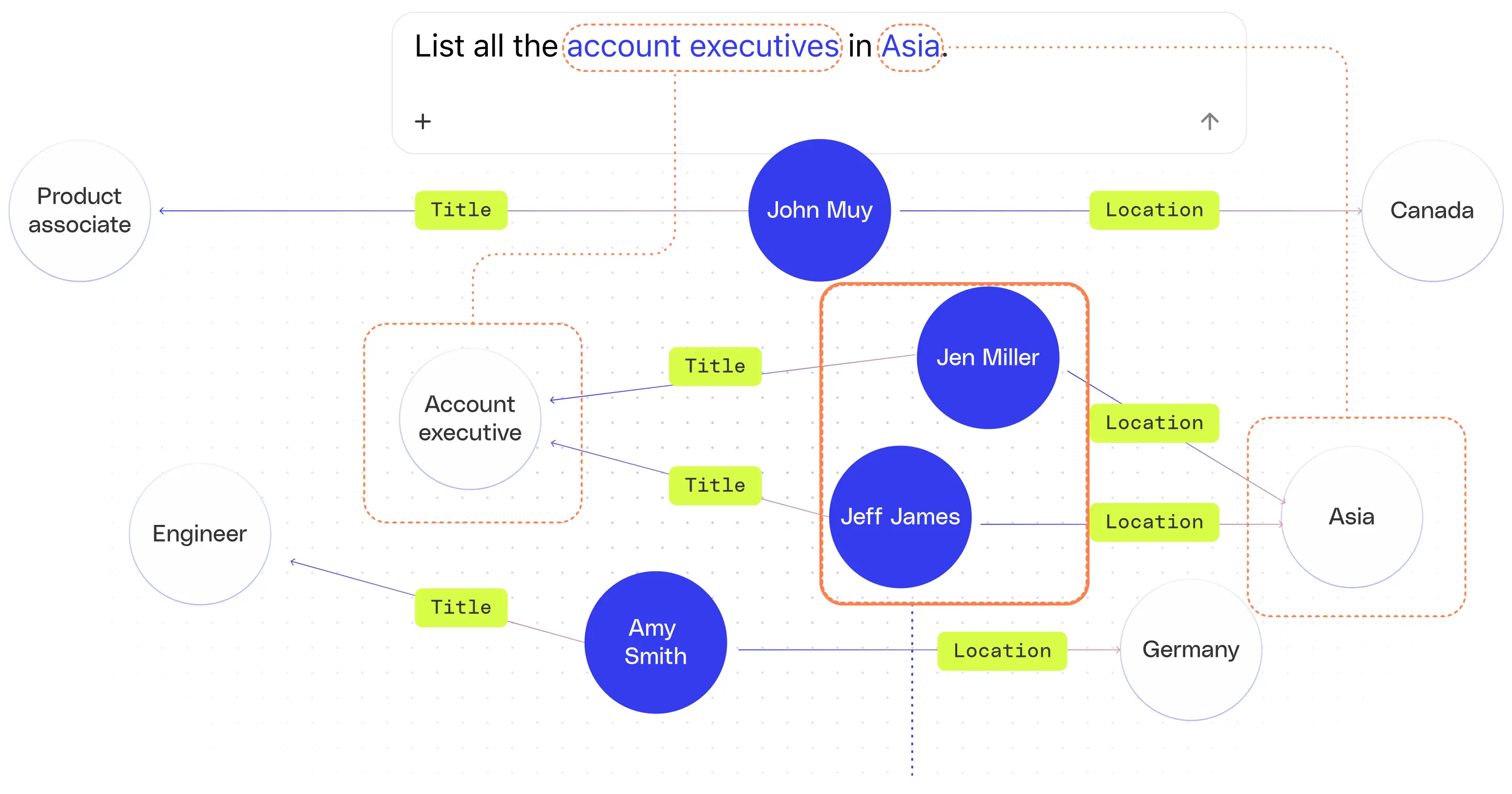
ナレッジグラフは、クエリを既知の構造化されたエンティティに基づいて行うことで、これらの問題を軽減するのに役立ちます。次の図に示すように、「アジアのすべてのアカウントエグゼクティブを一覧表示」するように求められた場合、ナレッジグラフでは、「アカウントエグゼクティブ」というクエリ用語を一般的な説明ではなく特定の職務として識別し、「アジア」というクエリ用語を場所として識別できます。この情報に基づいて、システムは、アジアにおけるアカウントエグゼクティブの役割と所在地を持つすべての従業員を対象に、網羅的で決定的な構造化されたクエリを実行できます。これはLLMだけでも一貫して取り組むのに苦労していることです。
LLMはエンティティ間の関係に苦労している
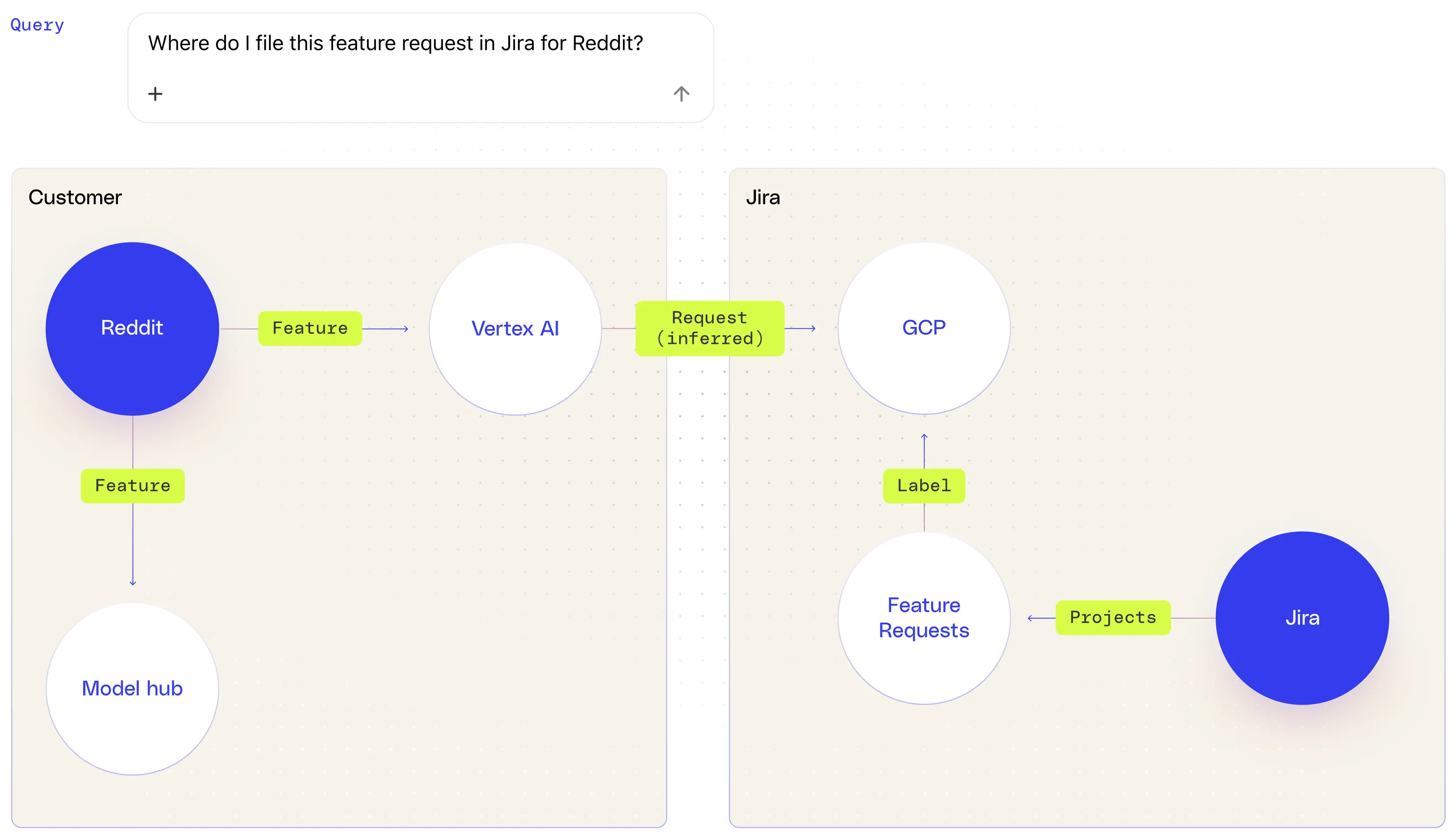
「Redditの機能リクエストはどこで提出すればいいの?」という回答など、より複雑なタスクの場合—LLMは、ソーシャルプラットフォームであるRedditと企業顧客であるRedditを明確にし、そのプロセスにはJiraが関与していることを認識し、これらの理解を一貫したワークフローに結び付ける必要があります。このようなレベルのリレーショナル推論とマルチホップ推論は、これらのエンティティ、ロール、システムをまとめてマッピングする機械可読のナレッジグラフがなければ、確実に実現することは困難です。
LLMには一貫した信頼性があります。LLMは、簡単に事実を思い出すために、信頼できる正しい回答を提供することができます。特に、回答が明確で、アクセスしやすいコンテキストに近い場合は、100% の確率で回答できます。より複雑なマルチホップ推論、または間接推論(「2025年第1四半期に出荷されたXが主導したプロジェクトのコードベースをすべて表示」)では、LLMの信頼性が低下します。すべてが揃っていれば正しく答えられることもありますが、幻覚を見たり、つながりを逃したりすることがよくあります。LLMが堅調な領域の外には、難しい質問や微妙な質問が山積みされています。この領域では、パフォーマンスが急激に低下し、ナレッジグラフが主流です。
ナレッジグラフによる仕事の変革
経営幹部が把握しておくべき最も難しい質問の 1 つは、「Project X は OKR に対してどのような成果を上げているか」というものです。これは価値が高く、意図も高い質問であり、ほとんどのシステム、特にエンジニアリングのコンテキストでは答えるのが困難です。正確に対応するには、システムが複数のデータソース、特にコードの貢献度を相互に関連付け、それらを特定のプロジェクトで定義された目標と主要な結果にマッピングする必要があります。この相関関係により、プロジェクトが赤、黄、緑のどれで追跡されているかを評価できます。
課題は、どのコード変更がどの OKR に関連しているかを判断することです。LLMはここで苦労しています。なぜなら、これはナラティブ言語を解釈する作業ではないからです。コードは簡潔で構造化されており、プロジェクトやビジネス目標に結び付けるような直接的な注釈がないことがよくあります。変更の量も重要です。コードベース全体で何千ものコミットが存在する場合があり、特定のイニシアチブに関連するのはごく一部です。
LLMは、正しいシグナルが特定されたら進捗状況をまとめたり、散文を作成したりするのに優れていますが、そもそもそれらのシグナルを明らかにするのにはあまり適していません。そのためには、ディレクトリ、ファイル、コンポーネントなどのコードアーティファクトを特定のプロジェクトにマップできるシステムが必要です。これには、オフラインプロセス、プロジェクトメタデータ、ディレクトリ構造などのヒューリスティック(例:docbuilder/フォルダー)などが含まれます。これらはすべて、ナレッジグラフに入力される重要なコンポーネントです。
これらの関連付けが行われたら、生成された構造化された関係を、実行時に使用できるようにサービングパスに表示する必要があります。ここで重要になるのがナレッジグラフです。実行時にすばやくクエリを実行できる構造化された表現を提供するナレッジグラフです。
エンタープライズAIにおけるナレッジグラフの影響をさらに再考するために、さらにいくつかの例をご紹介します。
営業:製品機能のギャップや、それらのアカウントで繰り返されるP1サポートのエスカレーションが原因で、売れ行きが落ちるリスクのある高額取引はどれですか?
この質問では、マルチホップ推論を使用して顧客データ、製品機能、およびサポートチケットを分析します。
IT: サービス全体で複数の重複アラートがトリガーされるシステム障害はどれですか。また、ノイズを減らすにはどうすればよいでしょうか。
この質問では、インフラツールとオンコールのページングスケジュールを理解し、ログをさまざまなサービスに関連付け、ノイズを抑えるための冗長性を特定します。
HR: 従業員のオンボーディング活動の最新リストを個別に教えてください。
ナレッジグラフは、チームのアクティビティをツール、手順、文書などの主要なコンテキストとともにキャプチャし、その情報を使用してLLMがオンボーディングタスクの優先順位を付けて常に最新の状態に保つことができるため、オンボーディングをスピードアップできます。
個人:業績評価のための自己評価を書くのを手伝ってください。
ナレッジグラフには、チーム、目標、協力者などの重要なコンテキストとともに、従業員の活動の包括的なリストが表示されます。LLMと組み合わせることで、質の高い自己評価の作成と改善のプロセスを大幅にスピードアップできます。
エンタープライズナレッジグラフの難しい部分
企業では、高品質のナレッジグラフを構築することは、GoogleやBingで見られるようなナレッジグラフを作成することとは根本的に異なり、またその点もより困難です。主な課題は、プライバシーの機密性、スケーラブルなアルゴリズムの必要性、入手可能な文書が比較的少ない場合に主要な実体や事実を特定することの難しさであり、手作業によるレビューは選択肢にない。
公開されているWebデータとは異なり、企業情報には、自由にアクセスしたり、手動で確認したり、(公開グラフプロジェクトでは一般的なように)人間のアノテーターチームに公開したりすることができない機密性の高いコンテンツ、または規制対象のコンテンツが含まれていることがよくあります。エンティティ抽出のすべてのステップは、組織のプライバシー、契約上、および法的境界を尊重する必要があります。グラフは、従業員がさまざまなレベルでデータにアクセスできるように構成する必要があります。これは、コンシューマーグラフが設計する必要のないものです。公開環境では、チームは公開されている膨大な量のデータを閲覧して、重要な事実を手動で整理できます。
企業では、手動によるレビューで「データを汚す」ことは禁止されているか、プライバシーと量の理由から大規模では禁止されているか、現実的ではありません。手作業によるグラフ作成は、それぞれが独自のデータ、ボキャブラリ、セキュリティ上の機密性を持つ何千もの多様な企業顧客に対応できるわけではありません。人間の介入なしにすべての顧客のコーパスを処理し、新しいデータが到着したときに動的に適応するには、アルゴリズムに基づいた自動化された方法が不可欠です。直接検査せずに抽出するプロセスには、エンタープライズAIにおける以下のステップが含まれます。
- 名詞の自動抽出:まず、コーパス上でアルゴリズム (NLP名詞フレーズ抽出など) を実行して、潜在的なエンティティをすべて抽出します。人間によるデータの確認は不要です。
- 頻度とプロミネンスのフィルタリング:よく使われる用語のすべてが重要なわけではありません。最初の抽出後、一般的な用語(「表」、「スペイン語」)は、統計的およびヒューリスティック主導の方法を使用して除外されます。
- エンティティの重要性の証拠:エンティティをナレッジグラフに昇格させるには、次のような追加のシグナルを使用して目立つかどうかを判断します。
- 主要文書のタイトルにおける存在
- 人気のあるリソース間での頻繁なリンク
- 上位共有ファイルまたはアクセス先ファイルでの発生
- 選択的特性の抽出と述語の識別:アルゴリズムは、浮上した各エンティティについて、記述的な用語と考えられる関係 (述語) を抽出し、やはり強力で再現可能な証拠が存在する事実 (「人が書いた文書」、「プロジェクト主導のプロジェクト」など) を優先します。
- 継続的なアルゴリズム改良:個人データを人間が読み取ることはないため、システムはフィルターを繰り返し改善して、過剰包含のリスク (価値の低いエンティティでグラフが漏れたり肥大化したりする) を減らし、各企業の新しいデータ構造やシグナルに適応します。
Glean では、セマンティック検索とレキシカル検索の両方を強化し、エンタープライズコンテンツとメタデータを継続的に取り込むリアルタイムクローラーアーキテクチャを構築しました。これと同じインフラストラクチャがナレッジグラフにも役立ち、強固な基盤となっています。過去6年間にわたり、このグラフを専用のアルゴリズムで改良し、ますます複雑化する推論とエージェントに求められるエンタープライズワークフローをサポートしてきました。
パーソナルグラフによるナレッジグラフの構築
最近、エンタープライズナレッジグラフに新しい次元が追加されました。個人グラフは、従業員のアクティビティをキャプチャして、個人が何に取り組んでいるか、その取り組みの影響を把握できます。目標は、進行中のプロジェクト、コラボレーションパターン、進行中のタスクを特定して、実際の作業をモデル化することです。これにより、Glean は、優先事項の明確化、対立の強調表示、ユーザーの整理支援など、積極的な支援を提供できるようになります。
しかし、パーソナルグラフは、関連性を調整したり、Glean 内のインタラクション履歴をキャプチャしたりするだけではありません。Glean エクスペリエンスをパーソナライズするための基盤となり、アシスタントの応答を強化し、状況認識型のエージェントに指示します。セッション履歴に依存する一般的なAIチャットツールのメモリシステムとは異なり、パーソナルグラフは、ツール、システム、時間を問わず、個人のデジタルアクティビティを総合的に調べます。
これをサポートするために、クロールインフラストラクチャを拡張し、読書行動や受動的な消費信号など、はるかに詳細なデータをキャプチャして、高密度のデジタルアクティビティストリームをリアルタイムで生成しました。これにより、ユーザーの作業状況をその場で理解するための基礎が得られます。
パーソナルグラフを作成できるようになった主な理由の1つは、LLM推論の進歩です。従来の機械学習では、異なるソース間での直接的な識別子 (カレンダーの招待と関連するドキュメントへの編集を結び付ける) がないため、アクティビティシグナルの統合に苦労していました。LLMは、時系列のアクティビティストリームを処理し、それらを推論して、関連するアクションを論理単位(タスク、プロジェクト、テーマ別の作業クラスタ)にグループ化できます。シグナルがまばらでタスクが切り替わっている場合でも、関連アクションを論理的な単位(タスク、プロジェクト、テーマ別の作業クラスタ)にグループ化できます。
Glean では、各アトミックアクション (「作成されたドキュメントX」、「ミーティングへの出席 Y」、「実行された内部ツールZ」) をサブタスクにまとめ、「ドラフトされた製品概要」や「法的要請に応じた」などのコンテキストに応じたラベルが付いた上位レベルのタスクにまとめています。システムはさらに、製品発売に関連する複数の文書など、関連するタスクをテーマごとに集約し、それらをOKRなどの組織目標にマッピングします。コラボレーションのパターン (繰り返されるコメントのやり取り、共有の Slack チャンネル) を分析することで、個人グラフでは何が行われているかだけでなく、誰がどのように協力しているかが明らかになり、企業内の仕事のダイナミクスの全体像を把握できます。
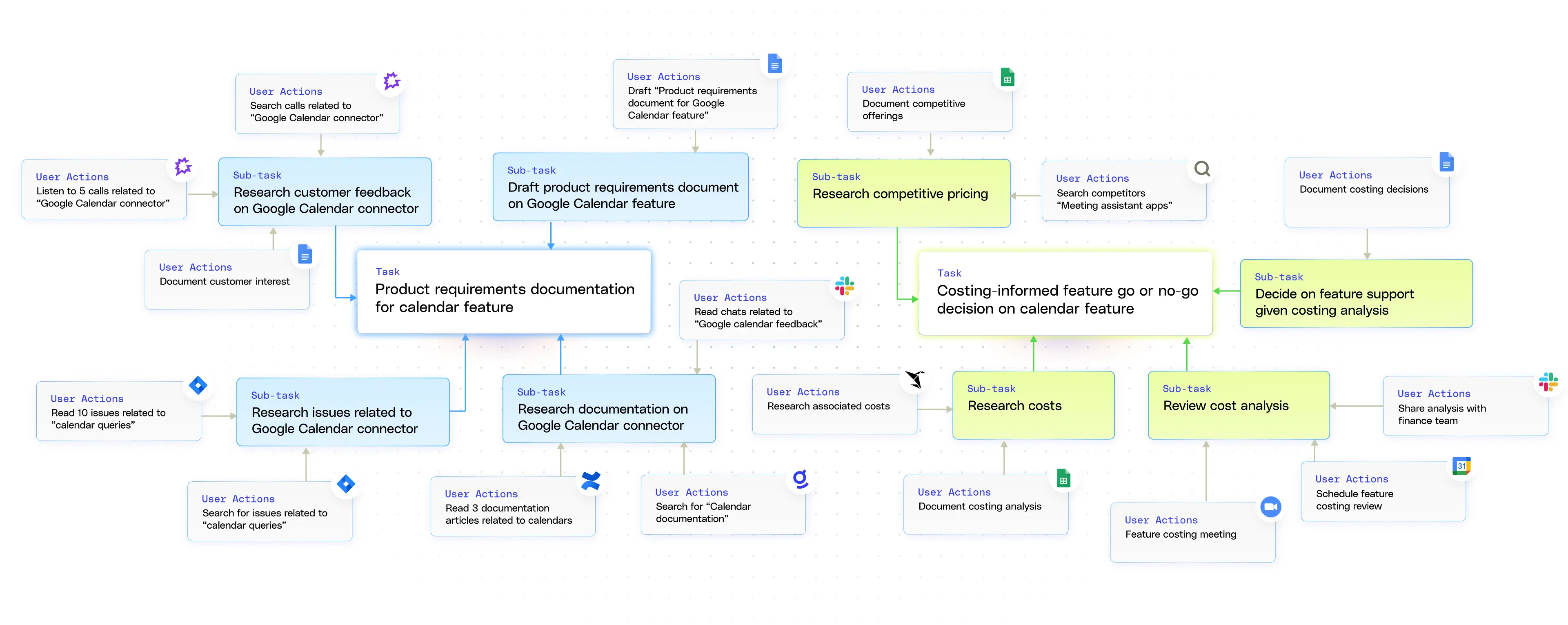
パーソナルグラフの作成は簡単ではありません。1つは、重要な仕事のすべてがデジタル(対面での会議やディスカッション)であるとは限らないことです。デジタル活動の中でも、真の意図を推測できる(ドキュメント編集はメジャードラフト、フィックス、それともポリッシュ?)ユーザーが明示的にマークした場合にのみ可能な場合があります(ドキュメントタイトルの「First Draft」)。そのため、パーソナルグラフを作成する際に、適切なシグナルを取得することが難しくなります。
私たちのクローラーアーキテクチャは、ここから重要なスタートを切るのに役立ちます。これは、すべてのデータソースに独自のスキーマがあるためです (「コメント」の意味は Jira、GDocs、メールなどによって異なります)。企業でマルチソース推論を可能にするには、ソースにとらわれない共通の言語と時系列データベースを作成する必要があります。これは、最初にデータのインデックスを作成することによってのみ可能です。 フェデレーテッドサーチ ソース間の点をつなぐのに必要な構造や信号を提供していません。
Glean では、ユーザーが先週取り組んだ作業をまとめたり、業績評価の準備をしたりするのに役立つクイックスタートエージェントとともに、パーソナルグラフをすでに活用しています。これらのエージェントはフィードバックループを提供してくれるので、パーソナルグラフを継続的に繰り返し処理できます。
Gleanの幅広いコンテキストの視野こそが、企業全体でAIを水平的に提供することを可能にしているのです。Glean は単に質問に答えるだけではありません。あなたの働き方を学び、パーソナライズされた専門的な AI アシスタントおよびエージェントプラットフォームになるために、あなたと一緒に適応していくことです。
エンタープライズ AI におけるコンテキストシステム
エンタープライズナレッジグラフとパーソナルグラフを組み合わせると、複雑でリスクの高い意思決定をサポートできるだけでなく、組織とその中の個人の両方にとって個人的なものと感じられる方法で支援できるようになります。
企業におけるアシスタントとエージェントの将来について考えると、パーソナライゼーションはレスポンスの調整にとどまりません。これらのシステムでは、ニーズを予測して、問題になる前に障害を解決し、行き詰まった取り組みを明らかにし、目標に向かってユーザーを積極的に指導する必要があります。それが私たちが向かっているところです。
これまで、どの組織にとっても間違いなく最も重要な資産であるエンタープライズデータと人材という2つの重要なレイヤーに焦点を当ててきました。しかし、3 つ目のレイヤーがあります。プロセスとは、実際に人とエージェントの両方が仕事をどのように行うかということです。
プロセスは、それを設計する人々によって形作られ、深く個人的なものになることがあります。しかし、多くの人は、一人の個人から離れて、バックグラウンドで口ずさみもします。私たちは両方から学びます。人々がデータ、システム、ツールをどのように扱い、エージェントがどのように使用されているかを観察することで、これらのプロセスをシステム自体の一部として明らかにし、モデル化し始めます。
この進化する状況は、データや人と切り離された存在ではなく、その上に構築される新たなコンテクストレイヤーを生み出します。ウェブが動いているのを見ると、コンテクストシステムは単に情報を整理することではなく、コンテクストインテリジェンスを調整することだと気づくでしょう。データは出発点ですが、そこから生まれるのは、あらゆるAIインタラクションに継続的に適応し、学習し、適切なコンテキストをもたらすネットワークです。
このように見ると、エージェントシステムの認知力はLLMだけではないことが明らかになります。コンテキストシステムもそうです。



