




.png)
Today, federated search is re-emerging, spurred by new connectors from OpenAI, Google Agentspace, and open protocols like the Model Context Protocol (MCP). Many enterprises are now asking: have LLMs found a shortcut to grounding agents in enterprise context, fundamentally changing the need for an index?
When we started Glean, consumer search had matured—built on decades of progress in information retrieval and large-scale machine learning. Enterprise search, by contrast, remained unsolved. Organizational knowledge was fragmented across hundreds of SaaS applications, each with its own data model and access patterns. Delivering relevance often involved heavy-handed tuning, yet still produced low-quality results.
From the outset, we believed that enterprise users deserve search that matches the speed, precision, and intuitiveness of consumer search. However, we recognized that standard could not be achieved using federated search. Federated search yields latency-prone, partial results due to data model mismatches and a lack of unified ranking.
Instead, real enterprise search requires foundational infrastructure and applied machine learning: connectors, crawlers, data normalization, permission-aware indexes, knowledge graphs, and a ranking engine tuned to enterprise context.
Over the years, Glean has heavily invested in building this stack—running hundreds of A/B experiments, adapting our architecture to support new data modalities and evolving API rate limits, and continuously scaling with the growing complexity of modern SaaS ecosystems.
LLMs have changed how we interact with information—but rather than making indexes obsolete, they’ve made them even more essential. Indexes continue to offer the most cost-effective and performant way to ground intelligent systems in enterprise knowledge.
The drawbacks of federated search
Federated search sends user queries to multiple external data sources—like Google Drive, Jira, or Salesforce—in real time. Each source executes the query independently and returns separate results. Finally, the federated system aggregates these results into a single list for the user. Sounds simple, but it’s a sub-optimal solution in large enterprise environments.
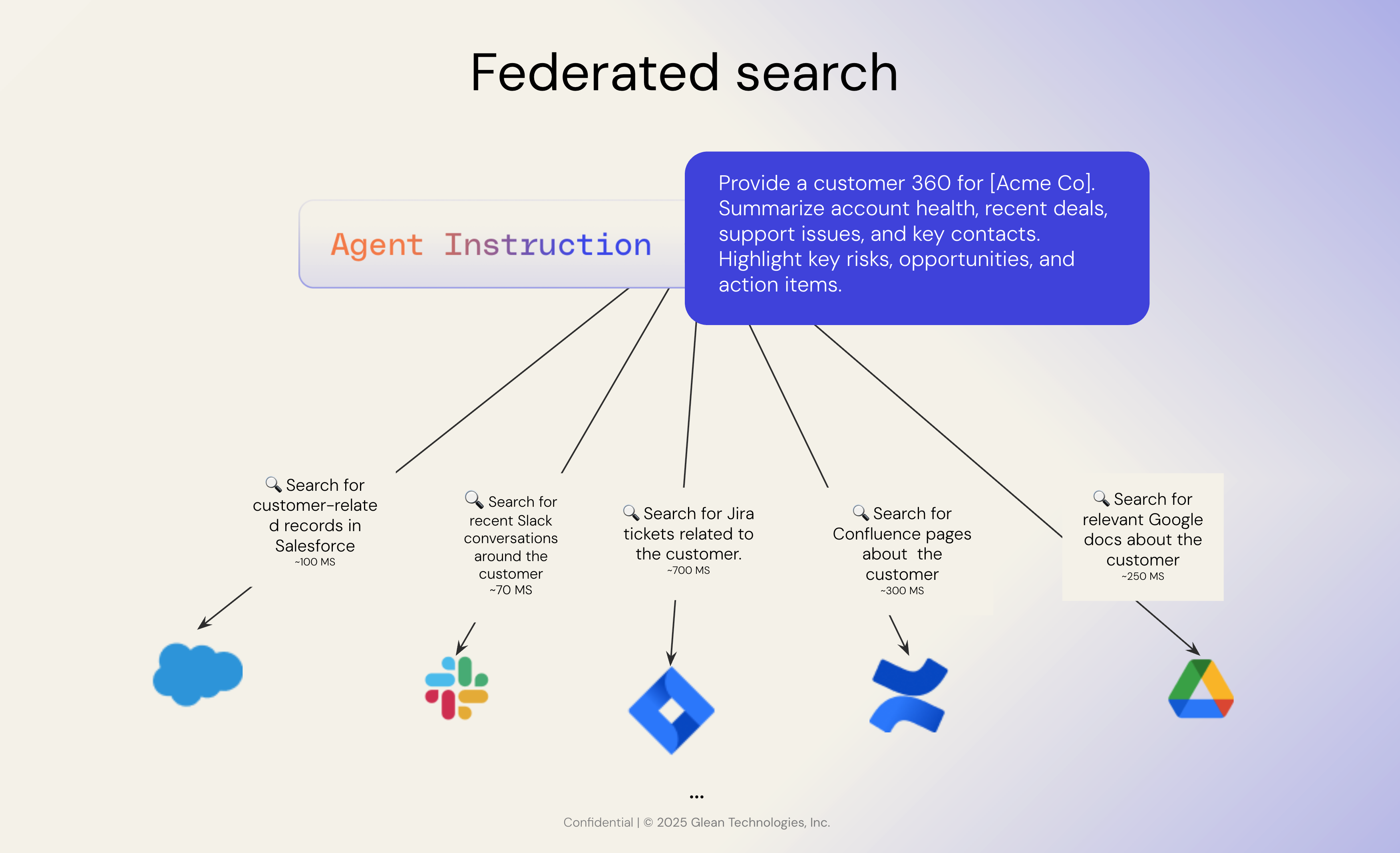
1. Multiple API calls, all at different speeds
Federated search requires calling every individual application in parallel—and waiting for all responses to come back before displaying results. In enterprises, this can mean querying dozens of sources. Because each API responds at its own pace, you’re only as fast as the slowest system. This leads to a laggy and inconsistent search experience.
2. Limited to user-authenticated data
Most federated systems only return results that the current user is authorized to see via the API. This means you're often limited to that user’s personal data slice, missing the broader organizational context that gives search its value—such as document popularity, collaboration signals, and who else in the company is engaging with that content. Without that metadata, content lacks relevance. The benefit of user-authentication is that it's easily permissioned search, the drawback is that it’s missing key context.
3. Inconsistent and low-quality search APIs
Each third-party application has its own API, often designed for basic retrieval—not enterprise-grade search. Many are slow, incomplete, or poorly maintained. These APIs aren’t optimized for search relevance; they’re often provided as a convenience, not a core product. Most SaaS companies don’t purport to be search experts, and some are as simple as basic keyword search.
4. Simple, rule-based ranking
Because there’s no centralized index, federated systems can’t normalize data across sources. This makes it impossible to apply a consistent ranking model. Instead, you’re left with simplistic, rule-based logic that can’t reason across heterogeneous data formats. You may choose to rank some data sources over others, using simple heuristics based on the query patterns.
In the federated search example, I could choose to weight results based solely on their data source. But doing so risks excluding highly relevant results—simply because they came from a lower-priority source—which means they might not make it into the LLM’s context window when generating a response.
1SOURCE_WEIGHTS = {
2 "salesforce": 1.5, # Higher trust for structured customer data
3 "jira": 1.4, # High value for engineering/project context
4 "confluent": 1.2, # Moderate, technical internal comms
5 "slack": 1.0, # Recency/urgency signals
6 "gdocs": 1.0 # General documentation
7}5. Filtering suffers from the lowest common denominator
If one of the connected systems doesn’t support a specific filter—say, filtering by last modified date—then that filter can’t be applied to the overall results. This creates a lowest-common-denominator effect, where the limitations of the weakest API define the capabilities of your search experience.
While federated search is experiencing renewed interest thanks to MCP simplifying how systems connect, it doesn’t actually improve the quality of search results—which is critical when those results are passed to LLMs. MCP is a communication protocol—a kind of “USB‑C port” for AI apps that enables interoperability—but it doesn’t address relevance. At Glean, we see MCP as a powerful way to extend our system of context to agents built anywhere, securely grounding them in enterprise data. It’s why we’ve invested in hosted MCP servers and embraced agent interoperability—to make our search and reasoning engine available wherever agents run.
How indexes make a difference
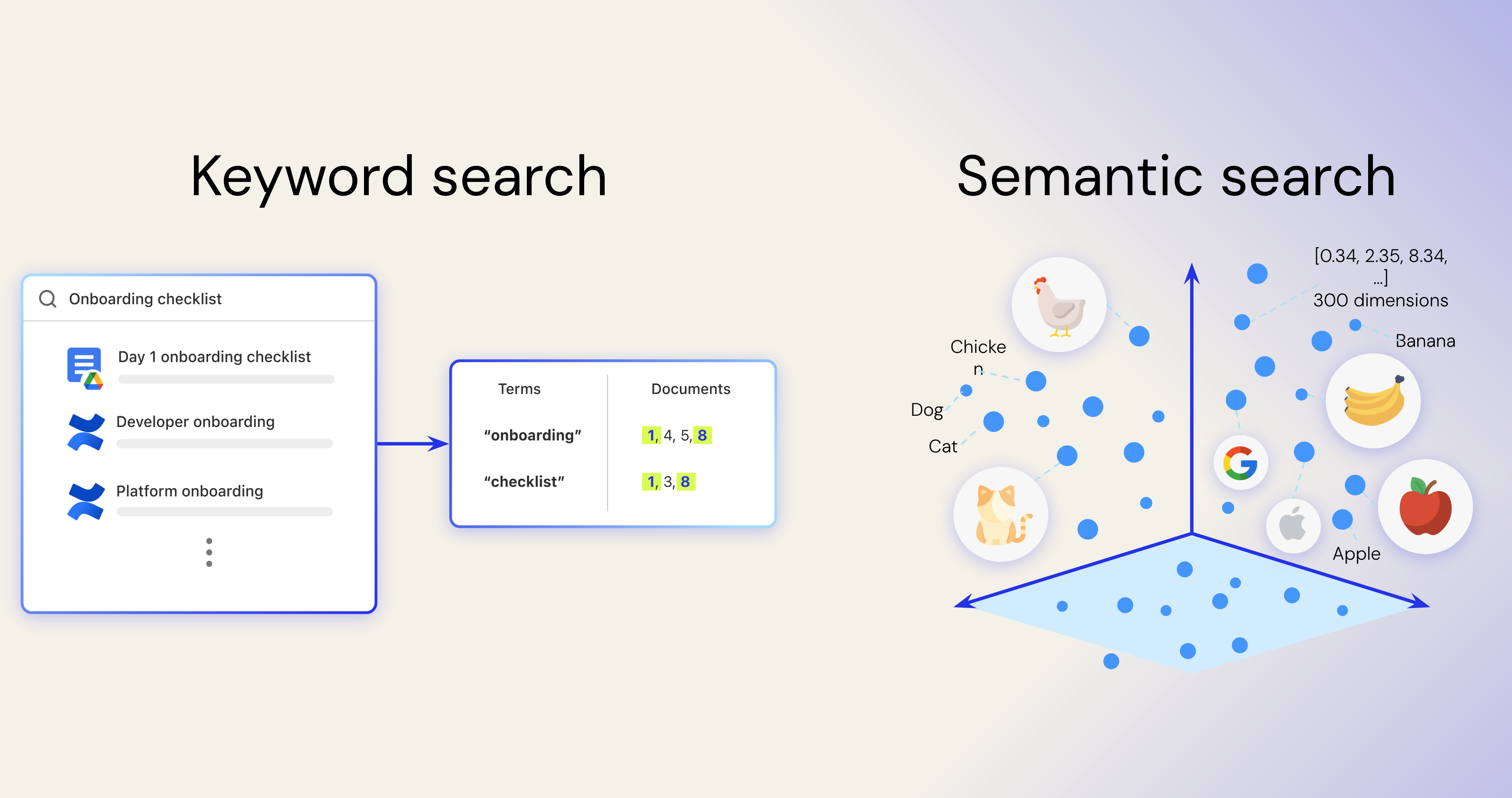
The simplest analogy for an index is the back of a book: it maps terms to locations, making information easy to find. That’s the foundation of traditional keyword search—and it still plays a critical role. But with the advent of language models like BERT, enterprise search evolved. These models introduced a deeper understanding of language by encoding meaning into high-dimensional vectors—bringing us from exact-match lookup to semantic understanding.
Like any data structure, indexes enable us to understand and use underlying data for fast, efficient retrieval.
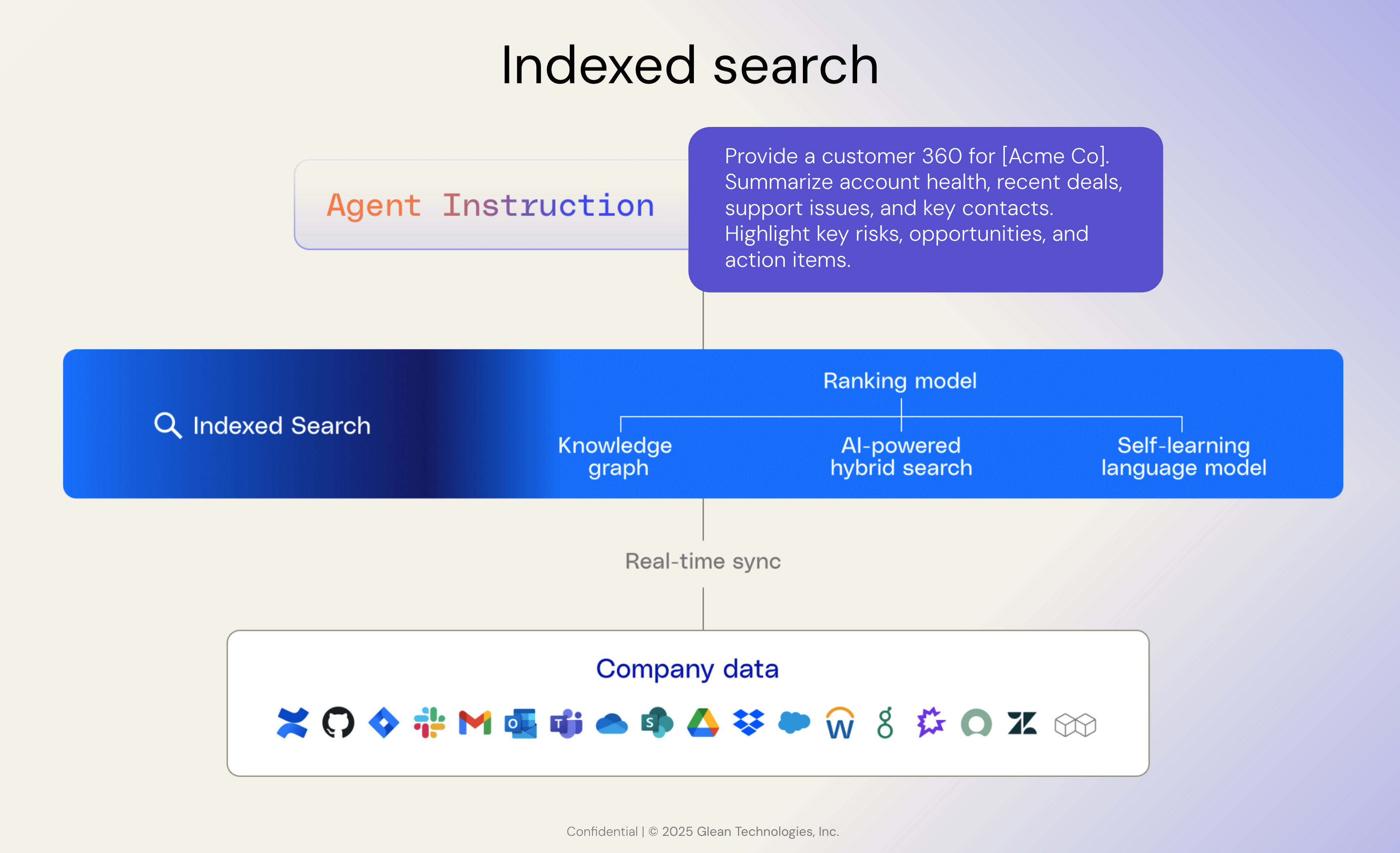
Indexes for enterprise search are their own beast and come with the following complex systems and science problems:
1. Custom crawlers
You need to determine what to crawl, how to respect rate limits, and how to extract not just content, but permissions and metadata. Crawlers must be intelligently prioritized—permission data often matters more than content—and they need backoff and retry logic to gracefully handle throttling and API failures.
2. Enterprise-adapted indexing & ranking
Lexical methods like BM25 and TF-IDF assume homogenous data—something diverse enterprise applications lack. Effective search requires building and refining indexing algorithms tailored to the complexities of enterprise content. For instance, comments are lower-value content that decays faster over time, and title-less messages in Slack need custom logic. That means the indexing algorithm needs to understand the design and value of each individual app.
Semantic search was foundational for enterprise search. It enabled search systems to go beyond literal keywords, learning how internal names relate to concepts. In Glean, we internally refer to our “query engine” as “Scholastic” rather than the children’s magazine, semantic search is able to make that association. By training on a unique enterprise corpus, semantic indexes can find content that a federated search would miss.
3. Entity-level understanding using knowledge graphs
An index alone doesn’t capture relationships. Simply knowing that a term appears in a document isn’t enough—you need to understand what that term refers to. Is it a customer? A technology? A teammate?
Humans naturally make these kinds of associations when reading content, but LLMs need structured context to do the same. Without it, they can confuse similar-looking terms and make incorrect assumptions. This happens often with product names or versions in the enterprise—like Gemini 2.5 Pro vs. Gemini 2.0 Flash. An LLM might accidentally conflate the two, leading to inaccurate responses.

4. Continuous experimentation
Search isn’t static. You have to run live experiments to improve search and agent results. There are also always new entities and data points that need to be added to a search experience.
At Glean, we’ve run 100s of experiments to determine the following solutions to authority, cost-start deployments, and changing search patterns with the rise of semantic search and agents:
- Cold-start deployment: We bootstrap new environments with high-quality public and synthetic training data to deliver value on day one.
- Topicality-aware ranking: Elevates evergreen content like HR policies, even if they’re old or infrequently accessed.
- Calibration loops: We continuously refine our self-learning ranking models to adapt to changing behaviors, use cases, and query patterns.
In the last few years we’ve seen search patterns in the enterprise evolve. Short keyword queries have evolved into longer, more open-ended questions—driven by the rise of AI. New query and agent patterns are emerging too: enumeration, ticketing, expert lookups, customer 360s, and more—reflecting the diverse ways people are engaging with AI at work. As the ways people generate and interact with data expand, the underlying search intelligence must evolve as well.
The role of indexes with LLMs
Even with powerful LLMs, relying on indexed enterprise data—rather than training models on it—offers a safer, more flexible approach. Indexing extends a model’s knowledge without embedding sensitive data directly into the model, keeping information secure and governed through permissions-aware retrieval. Unlike fine-tuned models, which become static and hard to update, indexed data stays live and responsive to changes—ensuring compliant and up-to-date results. LLMs alone are insufficient for secure enterprise AI.
There’s been a growing push toward larger context windows, giving LLMs access to more data when making decisions. A common question that follows is: if the model can see more, does precision in search still matter? At Glean, we’ve found the answer to be yes. Bigger context windows don’t fix poor inputs—when contradictory or irrelevant information is packed in, it often leads to confusion and inaccurate responses. It’s not just about how much data you provide—it’s about curating the right context. This takes even more importance as we evolve from info-finding to agentic use cases. The best way to get deterministic results out of an agent is to supply the exact right info to the LLM per agent step.
We’ve also seen interest in pairing federated connectors with deep reasoning. While deep reasoning can help mask the latency of federated search and allow for more iterative LLM calls, it’s a costly workaround. When data is already indexed, models can respond faster and reason more deeply in the same amount of time. Without that, the LLM spends time waiting on slow federated endpoints and compensates for imprecision with excessive rounds of reasoning—something indexed search avoids.
With the graduation from assistants to agents, the grounding in enterprise data becomes even more important because agents are taking autonomous actions. The index is just one piece of the puzzle—building knowledge graphs on top of the index is what brings the context to agents. This is essential for enterprise users wanting a simple way to use agents—directing them through natural language instructions, with the agentic reasoning engine orchestrating all the back-end context, actions, and triggers.
You can’t get to that seamless experience without a centralized index across all horizontal enterprise data. Forgetting that index means recreating for AI the same data siloes that occurred in SaaS—or boxing yourself into a small and soon-to-be-outdated data set for every agent.



