







- Open, interoperable agent architectures are essential for enterprises to avoid vendor lock-in, enable rapid adoption of new AI capabilities, and ensure that each layer of the stack—context, models, orchestration, interfaces, and security—can evolve independently while working together.
- Building a robust context layer is critical for effective AI agents; it requires unified, permissioned data, advanced context engineering, and separation from the model layer to preserve enterprise knowledge and flexibility across different AI providers.
- Horizontal orchestration and centralized security are necessary to scale agent deployments across organizations, allowing agents to automate complex workflows reliably and securely, while domain-specific interfaces ensure agents are embedded where real work happens.
In 2025, the concept of an “agent” really took root: AI that can reason, iterate, and act on data to accomplish real work. Since then, we’ve seen a wave of open-source technologies emerge around agents: Agent SDKs, MCP, A2A, skills libraries, sandboxes, and other building blocks designed for open standards and interoperability. That openness matters. It’s what allows agents to take on more work: you can plug into more tools and push agents beyond a single chat box into IDEs, internal apps, and enterprise systems.
The models driving these agents got remarkably better at real work. They’re capable of writing and fixing code, reasoning through multi-step problems, generating complex images, and handling long-running tasks—even if those gains didn’t show up in benchmarks. As a result, we’ve seen more specialization of models: Claude for coding, GPT for reasoning, Nano Banana for image generation, with a new “wow” model every few months that opens up new capabilities. It only solidifies that the future is one of different models for different tasks.
Over the past year, teams pushed these agents hard to see how much work they could take on and how much “context engineering” was required to make that possible. The question everywhere was the same: What does it take to get agents to perform dependably enough for enterprise use? At Glean, we’ve seen this firsthand across support ticket resolution, sales account forecasting, and engineering debugging.
What’s now emerging is a shift from one-off agent experiments to building and operating dozens—sometimes hundreds—of agents inside a company. Individual employees are using agents to redefine personal productivity, and departments are re-thinking core business processes beyond the capability set of system of record apps. Organizations want something scalable: with dependable context, safe ways to use their data with AI, and the ability to absorb fast-moving innovations in models and tools without rebuilding their stack from scratch.
We’re seeing an acknowledgement of that agent stack take shape. You can see variants from every cloud vendor, from data platforms like Databricks and Snowflake, and from departmental system of record players like ServiceNow and Salesforce. Even model providers are creating agent platforms like OpenAI’s Frontier introduced last week.
Glean, of course, delivers an agent architecture that rides upon our deep foundation of enterprise context, data connectivity, and security. Unlike most, we’ve focused heavily on making our product into a stack that’s open at every layer. Today, I want to share more about that horizontal, open strategy
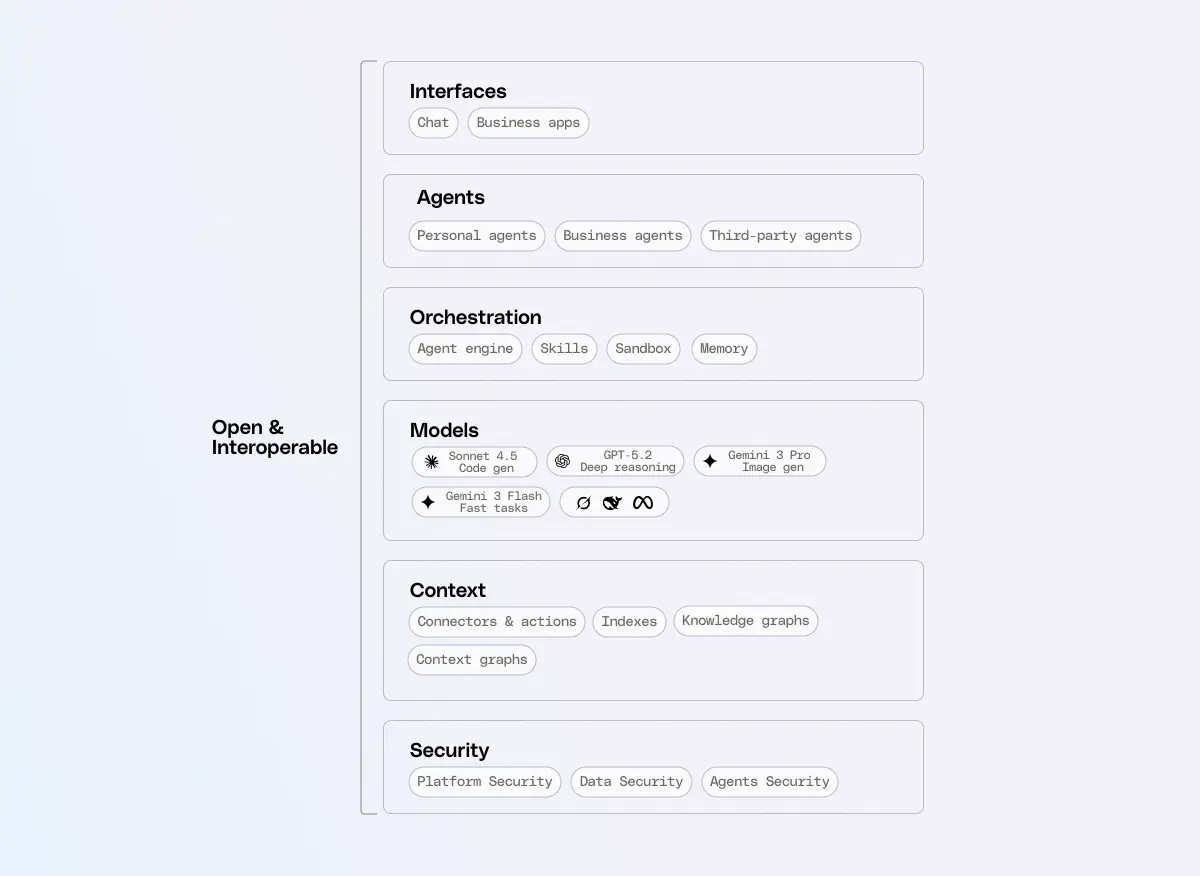
What I mean by an open strategy is that we’ve designed the agent architecture so it isn’t owned by a single player or technology. I like to think of it as a stack—the individual layers become too specialized for any one vendor to dominate them all. The strength of a stack is that its layers remain interoperable and mutually reinforcing: progress in one layer compounds the value of the others.
The pace of AI is unprecedented. More than ever, you don’t want to be the company that bets on a monolithic platform that locks you in- betting on a single player creates a single point of failure.
The enterprise agent stack
Context
Context engineering was coined in 2025 in the words of Andrej Karpathy: “When in every industrial-strength LLM app, context engineering is the delicate art and science of filling the context window with just the right information for the next step. Science because doing this right involves task descriptions and explanations, few shot examples, RAG, related (possibly multimodal) data, tools, state and history, compacting... Too little or of the wrong form and the LLM doesn't have the right context for optimal performance. Too much or too irrelevant and the LLM costs might go up and performance might come down. Doing this well is highly non-trivial. ”
It marked a turning point—models were finally being trained for tool use, and MCP emerged as a standard that brought tools into a wide range of AI-enabled apps. But context engineering also highlighted a real problem: wiring tools together is hard, and doing it over and over again for every new agent becomes a significant engineering burden.
To take that burden off engineers, you have to raise the stack. It’s not enough to hand teams off-the-shelf data endpoints and actions and hope they behave reliably in an enterprise environment. You need a contextualized foundation underneath:
- Data connectors that retrieve complete, permissioned information
- Indexes that deliver fast and accurate search
- Knowledge graphs that map relationships and enable multi-hop reasoning
- Context graphs that understand work processes
Without this foundation, you can’t get value from your data, decisions are ill-informed and incorrect, and you end up with what 2025 also gave us a name for: work slop.
What I’ve been excited to see over the holidays is that context has morphed from just understanding your data to understanding your enterprise and ways of working with context graphs. In past data eras, we only focused on recording the decisions (ie: the systems of record), not understanding how those decisions were made. But now, with agents, there’s value to understanding these processes—agentic automation. That’s giving agents more work to do because they can make better decisions by learning how work actually gets done.
There’s another reason why you want all your context in one place. It’s because every meaningful AI use case spans multiple systems. When each vertical product builds its own connectors, you get N copies of brittle integrations, inconsistent semantics, longer security reviews, and a growing maintenance burden.
Finally, enterprises we work with are beginning to understand that context is a key potential area of lock-in for the agent stack. If you spend years training an AI system to truly understand your enterprise, and build up its memory across years of interactions with all your employees and business processes, what happens when you want to move to a new AI model or a new vendor? Is all that context and learning lost, and must you start again? With the right agent architecture, you can separate all your context from the model layer. This ensures you retain your IP, and the valuable data within isn't locked to a single model or vendor.
Models
We wouldn’t be where we are with agents today without modern reasoning models. GPT-5 has pushed long-horizon reasoning forward, Claude remains the strongest on code and tool use, and Gemini Flash shows what’s possible with extremely fast, low-latency inference. Models today are remarkable in the range of work they can take on.
But despite the talk about commoditization, it’s clear we’re heading into a multiple-model, multiple-provider future. At Glean, we already select different models for different jobs—image generation, code generation, deep research, lightweight routing—regardless of provider. Different tasks need different models; that won’t change. Being model-agnostic ensures you always get access to the latest capabilities.
There’s also a more fundamental reason why model providers won’t own the context layer: the economics. Training costs have grown 2–3× per generation, with each frontier model now costing hundreds of millions of dollars in training compute alone. Only a handful of organizations can operate at this scale, which means frontier models become shared infrastructure rather than something every enterprise builds.
And this dividing line matters—model providers will stay focused on model development because building and maintaining the context layer is an entirely different, equally massive investment to get right.
Orchestration
There’s been a lot of discussion about orchestration lately, and for good reason. Orchestration is the closest thing we have to actual applications: it uses enterprise data, applies the right skills, orchestrates automation from business systems, and learns from repeated execution to reliably get work done. As a result, we’re going to see incredible orchestrators emerge for niche and departmental use cases, just like we’ve already seen with tools such as Cursor for engineering, Trupeer for product videos, and Airops for SEO content.
But there’s also a real need for horizontal orchestration, because those 100s of agents customized to your enterprise span multiple systems, teams, and data sources. That’s where a horizontal stack provides outsized value. At Glean, our focus is on AI that transforms how entire departments operate—support, sales, engineering, and beyond. To do that well, you have to understand how those functions actually work: their processes, handoffs, data flows, and decision points. Once you understand that, you can coordinate the right data and actions to automate real workflows.
If you zoom in, you’ll notice that the two parts of the stack that must be tightly coupled are the data layer and the orchestration layer. Without enterprise context—connectors, indexes, signals, process models, and relationships—an orchestrator can’t make good decisions or automate work reliably. And in the other direction, every agent run produces new traces and feedback that improve the context layer. Each execution teaches the system what worked, what didn’t, and how to optimize the next run.
This feedback loop—context informing orchestration, and orchestration strengthening context—is what makes reliable, long-running automation possible.
Security
Security is the one area where enterprises simply cannot tolerate fragmentation. If every point solution requires its own security model, you end up duplicating effort, widening your attack surface, and enforcing policies inconsistently.
Each wave of AI innovation—from RAG to agents to code generation—has introduced new security needs, requiring companies to develop new playbooks. Each AI wave needs to be built on the same security foundations: isolating data and models to prevent leakage, enforcing strong networking and encryption standards, and ensuring enterprise-grade identity through SSO.
What you really want from horizontal players is not the responsibility of figuring out how to protect each new innovation—you want security that is built in. When you search your enterprise data, sensitive content shouldn’t be surfaced accidentally. When you assign an agent a task, it shouldn’t take actions you didn’t authorize. When you generate code, it shouldn’t leak out of your private environment. These protections should be defaults.
You can take on that burden yourself, or you can partner with horizontal providers that apply a unified security model across your data, apps, and agent workflows. That realization—the need for consistent, centralized security—is one of the major forces driving consolidation of agent architectures.
Interfaces
We’ve spent much of 2025 anchored to the chat interface. And while chat isn’t going away, it won’t be the only way employees interact with agents. At Glean, we already see this in usage patterns: adoption is highest when agents are embedded directly into the business apps people use every day. As organizations introduce more agents, they’ll need those agents to show up wherever work happens.
That’s why I believe 2026 will usher in a new wave of agent interfaces. Above the horizontal layers of the stack, we’ll see vertical, domain-specific agents and UIs: support copilots for customer care, sales assistants, engineering productivity tools, CIO dashboards, HR and finance copilots, and embedded agents inside SaaS apps.
These experiences shouldn’t reinvent context and security—they should build on the layers that already exist—while layering on the domain-specific tools and workflows that make them useful. With the right agent architecture, you can build and train your enterprise context stack once, and connect it broadly across your enterprise in perpetuity.
The agent architecture
While enterprises are converging on AI platforms, they would be wise to not go monolithic: get one provider that tries to do everything, end up doing none of it deeply, and push the hard integration work back onto you, the customer. You’re left wiring tools, reconciling data models, bolting on governance, and stitching together workflows that should have been first-class citizens.
An open architecture mindset is different. It acknowledges that there is no single monolith that can keep pace with the speed of AI innovation. Instead, a stack is made up of differentiated layers—models, context & orchestration, interfaces—each of which can evolve independently while still working together. Stacks let vendors choose where they specialize, where they partner, and where they stay open for integration and new standards.
This approach is far more valuable for enterprises. It gives you flexibility without sacrificing quality, lets you adopt new capabilities the moment they appear, and prevents you from getting boxed into a closed ecosystem that can’t keep up. A well-designed agent stack is inherently future-proof and centralized because each horizontal layer can improve on its own timeline—without requiring you to rebuild the world around it.



