




.png)
現在、OpenAI、Google Agentspaceの新しいコネクター、および次のようなオープンプロトコルに拍車をかけて、フェデレーション検索が再び登場しています。 モデルコンテキストプロトコル (MCP)。現在、多くの企業が「LLMは企業環境におけるエージェントの基盤となる近道を見つけたことで、インデックスの必要性が根本的に変わった」という疑問が寄せられています。
私たちがGlean を始めたとき、情報検索と大規模な機械学習における数十年にわたる進歩に基づいて、消費者検索は成熟していました。対照的に、エンタープライズサーチは未解決のままでした。組織の知識は、それぞれが独自のデータモデルとアクセスパターンを持つ何百ものSaaSアプリケーションに分散していました。関連性を提供するにはしばしば手間のかかる調整が必要でしたが、それでも結果は低品質でした。
当初から、企業ユーザーには消費者検索のスピード、精度、直感性に匹敵する検索が必要だと考えていました。しかし、フェデレーテッドサーチでは標準を実現できないことが分かりました。フェデレーション検索では、データモデルの不一致や統一されたランキングの欠如が原因で、遅延が発生しやすい部分的な結果が得られます。
代わりに、実際のエンタープライズ検索には、コネクター、クローラー、データ正規化、権限対応インデックス、ナレッジグラフ、エンタープライズコンテキストに合わせて調整されたランキングエンジンなど、基本的なインフラストラクチャと応用機械学習が必要です。
Glean は長年にわたり、このスタックの構築に多額の投資を行ってきました。何百ものA/B実験を行い、新しいデータモダリティと進化するAPIレート制限をサポートするようにアーキテクチャを適応させ、現代のSaaSエコシステムの複雑さが増すにつれて継続的にスケーリングしてきました。
LLMは、私たちが情報を扱う方法を変えました。しかし、インデックスを時代遅れにするどころか、さらに重要性を増しています。インデックスは、インテリジェントシステムをエンタープライズナレッジに組み込むための最も費用対効果が高くパフォーマンスの高い方法であることに変わりはありません。
フェデレーション検索の欠点
フェデレーション検索は、Google ドライブ、Jira、Salesforce などの複数の外部データソースにユーザークエリをリアルタイムで送信します。各ソースはクエリを個別に実行し、個別の結果を返します。最後に、フェデレーションシステムは、これらの結果をユーザー用の 1 つのリストに集約します。シンプルに聞こえますが、大規模な企業環境では最適とは言えません。
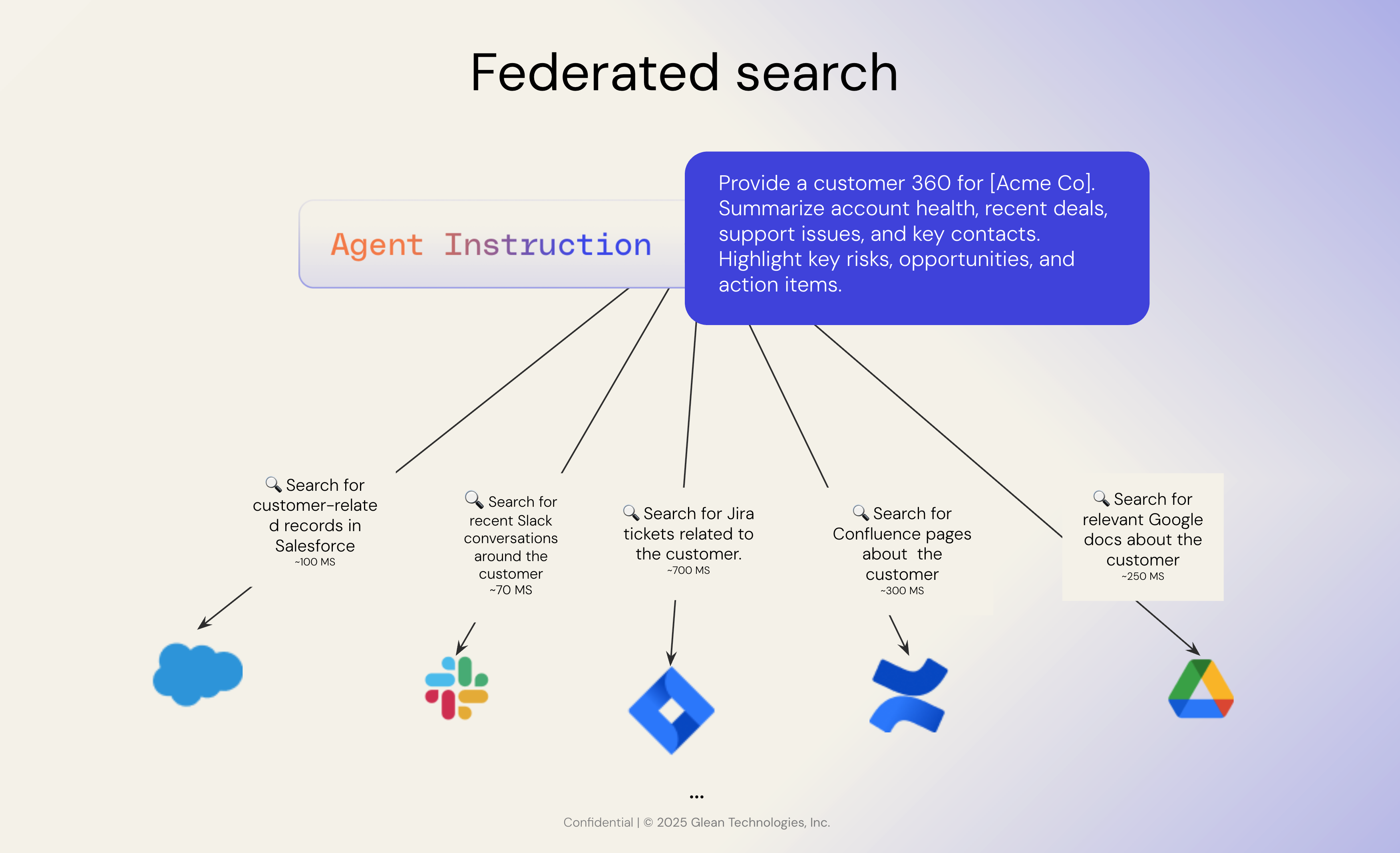
1。複数の API 呼び出しをすべて異なる速度で
フェデレーション検索では、個々のアプリケーションをすべて並行して呼び出し、すべての応答が返されるのを待ってから結果を表示する必要があります。企業では、これは何十ものソースにクエリを実行することを意味します。各 API はそれぞれ独自のペースで応答するため、最も遅いシステムと同じ速さしか得られません。これにより、検索エクスペリエンスが遅くなり、一貫性がなくなります。
2。ユーザー認証データに限定
ほとんどのフェデレーションシステムは、現在のユーザーに API を介して表示を許可されている結果のみを返します。つまり、ドキュメントの人気度やコラボレーションの合図、社内の他の誰がそのコンテンツに関わっているかなど、検索に価値をもたらす幅広い組織的背景を見逃してしまうことが多いということです。そのメタデータがなければ、コンテンツの関連性が失われます。ユーザー認証の利点は、検索を簡単に許可できることです。欠点は、キーコンテキストが欠落していることです。
3。一貫性がなく質の低い検索 API
サードパーティアプリケーションにはそれぞれ独自の API があり、多くの場合、エンタープライズグレードの検索ではなく、基本的な検索用に設計されています。多くは遅い、不完全、またはメンテナンスが不十分です。これらの API は検索の関連性を考慮して最適化されていません。多くの場合、コア製品ではなく、利便性を重視して提供されています。ほとんどのSaaS企業は検索の専門家を名乗っておらず、基本的なキーワード検索のように単純な企業もあります。
4。ルールベースのシンプルなランキング
一元化されたインデックスがないため、フェデレーションシステムはソース間でデータを正規化できません。これにより、一貫したランキングモデルを適用することが不可能になります。その代わり、異種のデータ形式では推論できない単純なルールベースのロジックが残ります。クエリパターンに基づく単純なヒューリスティックを使用して、一部のデータソースを他のデータソースよりもランク付けすることもできます。
フェデレーション検索の例では、データソースのみに基づいて結果を重み付けすることもできます。ただし、そうすると、優先度の低いソースからの結果であるという理由だけで、関連性の高い結果が除外されるリスクがあります。つまり、回答を生成するときに LLM のコンテキストウィンドウに表示されない可能性があります。
1SOURCE_WEIGHTS = {
2 "salesforce": 1.5, # Higher trust for structured customer data
3 "jira": 1.4, # High value for engineering/project context
4 "confluent": 1.2, # Moderate, technical internal comms
5 "slack": 1.0, # Recency/urgency signals
6 "gdocs": 1.0 # General documentation
7}5。フィルター処理には最低公約数の影響があります
接続システムのいずれかが特定のフィルター (最終更新日によるフィルターなど) をサポートしていない場合、そのフィルターは結果全体に適用できません。これにより、最も弱いAPIの制限によって検索エクスペリエンスの機能が決まるという、共通項が最も低い効果が生まれます。
MCPがシステムの接続方法を簡素化したおかげで、フェデレーテッド検索に新たな関心が寄せられていますが、実際には検索結果の品質が向上するわけではありません。これは、検索結果をLLMに渡す際に重要です。MCPは通信プロトコル、つまり相互運用性を可能にするAIアプリ用の「USB-Cポート」の一種ですが、関連性には対応していません。Glean では、MCPは、どこにでも構築されたエージェントにコンテキストシステムを拡張し、エンタープライズデータに安全に根付かせる強力な方法だと考えています。だからこそ、私たちはホスト型MCPサーバーに投資し、エージェントの相互運用性を採用しました。つまり、エージェントがどこにいても、検索と推論エンジンを利用できるようにしたのです。
インデックスが違いを生む仕組み
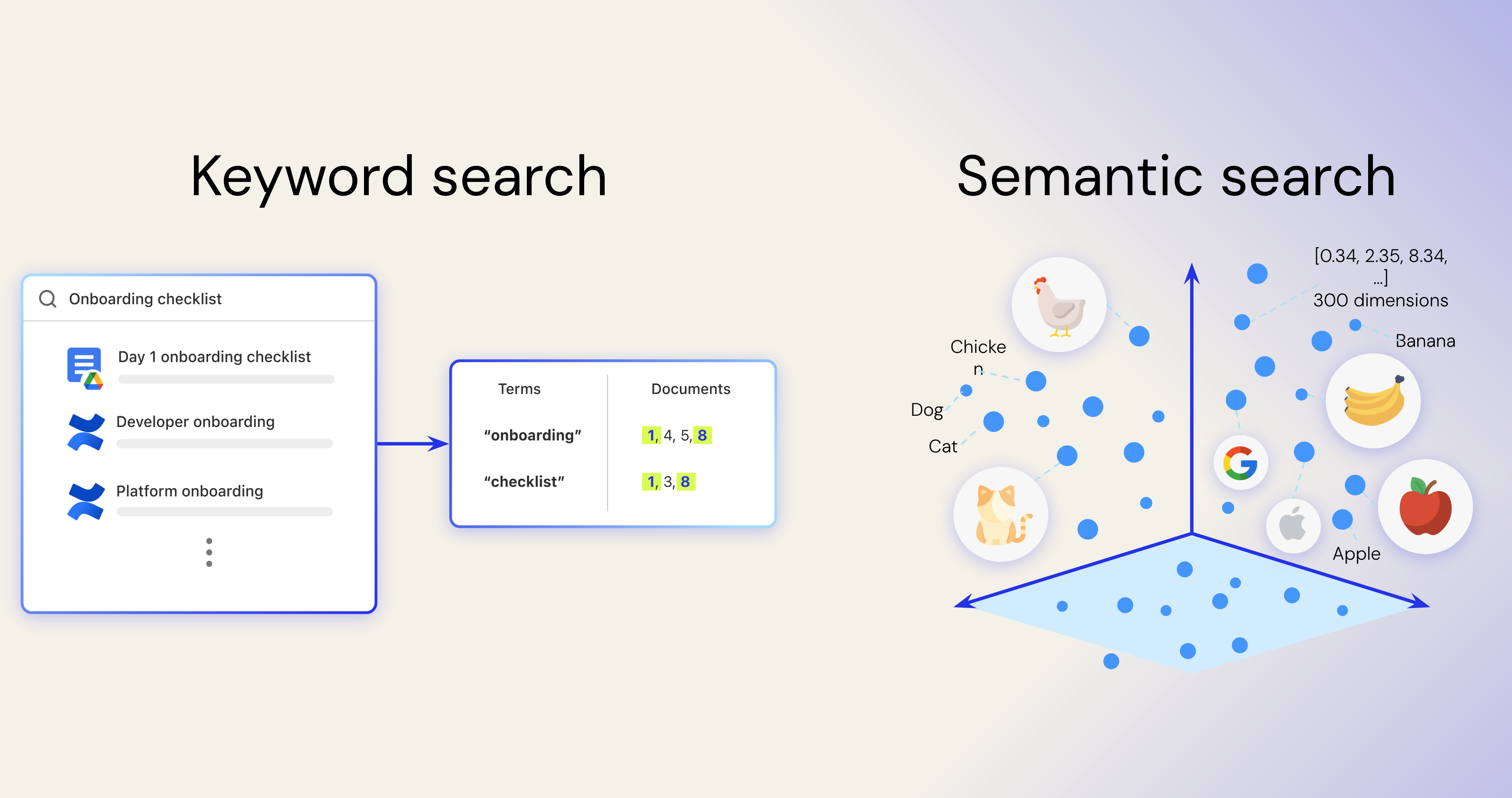
索引の最も簡単な例えは、本の表紙です。用語と場所が対応付けられているため、情報が見つけやすくなります。これは従来のキーワード検索の基礎であり、今でも重要な役割を果たしています。しかし、BERTのような言語モデルの出現により、エンタープライズサーチは進化しました。これらのモデルでは、意味を高次元のベクトルにエンコードすることで言語をより深く理解できるようになり、完全一致検索から意味論的理解へとつながりました。
他のデータ構造と同様に、インデックスを使用すると基礎となるデータを理解して使用できるため、すばやく効率的に取得できます。
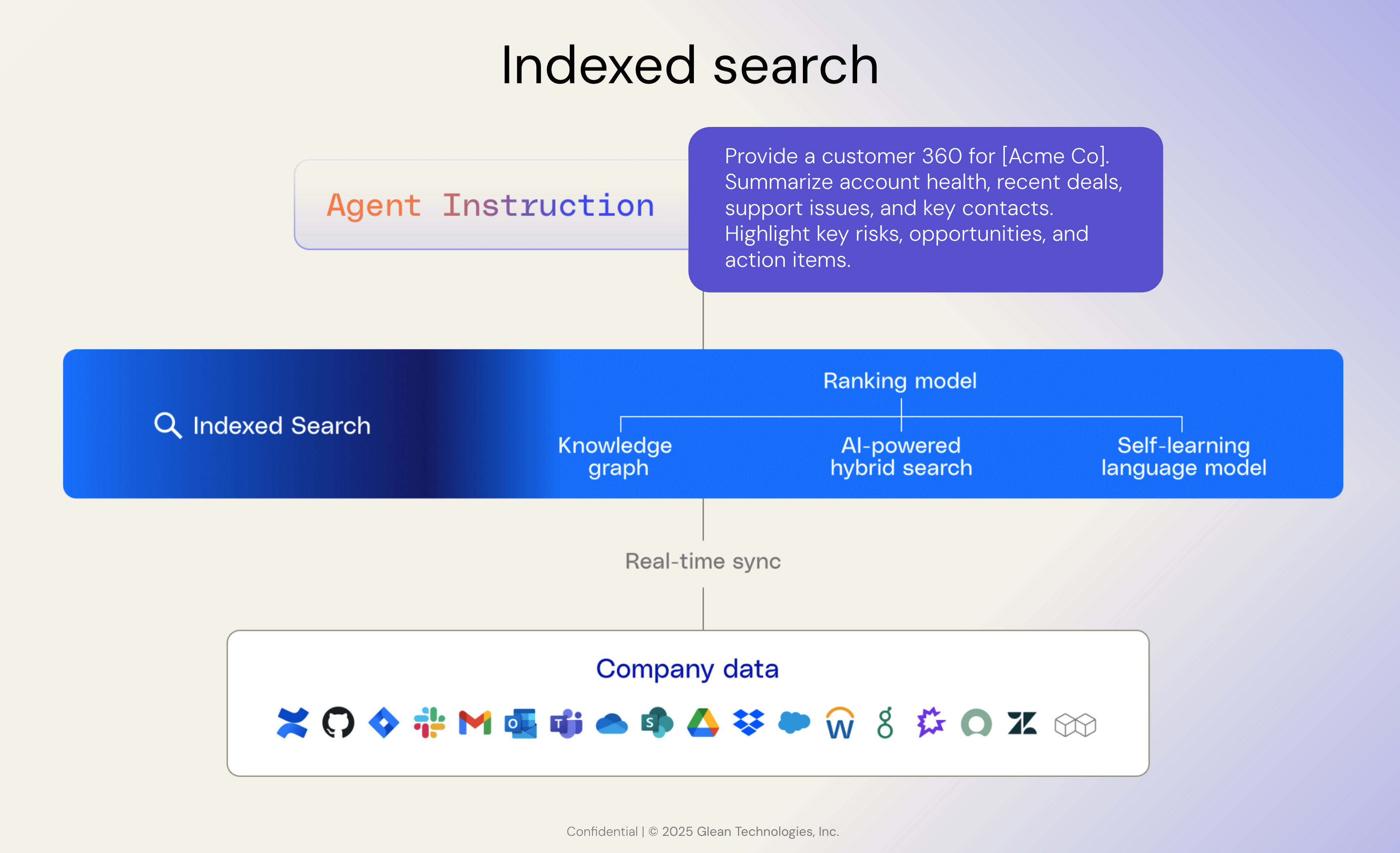
エンタープライズサーチのインデックスは、それ自体が最強のものであり、次のような複雑なシステムや科学的な問題を伴います。
1。カスタムクローラー
何をすべきかを決める必要があります クロール、 レート制限を尊重する方法と、コンテンツだけでなく権限やメタデータを抽出する方法もあります。クローラーはインテリジェントに優先順位を付ける必要があり、多くの場合、コンテンツよりも権限データの方が重要です。また、スロットリングや API の障害を正常に処理するには、ロジックをバックオフして再試行する必要があります。
2。エンタープライズ対応のインデックスとランキング
BM25やTF-IDFのようなレキシカル手法は、多様なエンタープライズアプリケーションにはない同種のデータを前提としています。効果的な検索を行うには、エンタープライズコンテンツの複雑さに合わせたインデックスアルゴリズムの構築と改良が必要です。たとえば、コメントは価値の低いコンテンツであり、時間が経つにつれて減衰が早くなり、Slack のタイトルのないメッセージにはカスタムロジックが必要です。つまり、インデックス作成アルゴリズムは、個々のアプリの設計と価値を理解する必要があります。
セマンティック検索はエンタープライズサーチの基礎でした。これにより、検索システムは文字通りのキーワードにとどまらず、内部名が概念とどのように関連しているかを学習できるようになりました。Glean では、社内で「クエリエンジン」を子供向け雑誌ではなく「Scholastic」と呼んでいますが、セマンティック検索ではその関連付けを行うことができます。セマンティックインデックスは、独自のエンタープライズコーパスでトレーニングを行うことで、統合検索では見落とされるコンテンツを見つけることができます。
3。によるエンティティレベルの理解 ナレッジグラフ
インデックスだけでは関係を把握できません。ある用語が文書に使われていることを知っているだけでは十分ではありません。その用語の意味を理解する必要があります。お客様ですか?テクノロジー?チームメイト?
人間はコンテンツを読むときに自然にこのような関連付けを行いますが、LLMでも同じことを行うには構造化されたコンテキストが必要です。これがないと、似たような用語を混同したり、誤った仮定をしたりする可能性があります。これは、Gemini 2.5 ProとGemini 2.0フラッシュの比較など、企業内の製品名やバージョンでよく発生します。LLMが誤ってこの2つを混同し、不正確な回答につながる可能性があります。

4。継続的な実験
検索は静的ではありません。検索とエージェントの結果を改善するには、ライブテストを実行する必要があります。また、検索機能に追加する必要のある新しいエンティティやデータポイントも常に存在します。
Glean では、セマンティック検索とエージェントの台頭による権限、コストスタートの導入、検索パターンの変化に対する次のようなソリューションを決定するために、何百回もの実験を行ってきました。
- コールドスタートデプロイ: 質の高い公開トレーニングデータと総合トレーニングデータを使用して新しい環境を立ち上げて、初日に価値を提供します。
- 話題性を意識したランキング: 古くなったり、アクセス頻度が低い場合でも、人事ポリシーなどのエバーグリーンコンテンツを向上させます。
- キャリブレーションループ: 私たちは、変化する行動、ユースケース、クエリパターンに適応するために、自己学習型のランキングモデルを継続的に改良しています。
ここ数年、企業における検索パターンは進化してきました。AIの台頭により、短いキーワードクエリは、より長く、より自由回答形式の質問へと進化しました。また、列挙、チケット発行、専門家による検索、顧客の360度分析など、新しいクエリパターンやエージェントパターンも登場しています。これは、人々が職場でAIと関わっているさまざまな方法を反映しています。人々がデータを生成して操作する方法が拡大するにつれて、基盤となる検索インテリジェンスも進化する必要があります。
LLMにおけるインデックスの役割
強力なLLMがあっても、モデルをトレーニングするのではなく、インデックス化された企業データに頼るほうが、より安全で柔軟なアプローチになります。インデックスを作成すると、機密データを直接モデルに埋め込むことなくモデルの知識を広げ、権限に応じた検索によって情報の安全性と管理を維持できます。静的で更新が難しい微調整モデルとは異なり、インデックス化されたデータは常に最新の状態に保たれ、変更に対応できるため、規制に準拠した最新の結果が保証されます。LLMだけでは、安全なエンタープライズAIには不十分です。
LLMが意思決定の際により多くのデータにアクセスできるようにすることで、コンテキストウィンドウを拡大する動きが高まっています。よく聞かれる質問は、「モデルがもっと見ることができるとしても、検索の精度は重要か?」というものです。Glean では、答えが「はい」であることがわかりました。コンテキストウィンドウを大きくしても、不適切な入力は修正されません。矛盾した情報や無関係な情報が詰め込まれていると、混乱や不正確な回答につながることがよくあります。重要なのは、提供するデータの量だけではなく、適切なコンテキストをキュレーションすることです。これは、情報検索からエージェントユースケースへと進化するにつれて、さらに重要になります。エージェントから確定的な結果を得る最良の方法は、エージェントステップごとに正確に正しい情報をLLMに提供することです。
また、フェデレーションコネクターと深い理屈を組み合わせることにも関心が寄せられています。深い推論はフェデレーション検索の待ち時間を隠し、より反復的な LLM 呼び出しを可能にするのに役立ちますが、これはコストのかかる回避策です。データがすでにインデックス化されている場合、モデルは同じ時間でより迅速に応答し、より深く推論できます。これがないと、LLM は速度が遅いフェデレーションエンドポイントでの待機に時間を費やし、インデックス検索では避けられる過剰な推論によって不正確さを補います。
アシスタントからエージェントへと移行するにつれ、エージェントは自律的な行動を取るようになり、企業データの基盤となることがさらに重要になります。インデックスはパズルの一部に過ぎません。インデックスの上にナレッジグラフを作成することで、エージェントにコンテキストを伝えることができます。これは、エージェントを簡単に使用する方法を求めるエンタープライズユーザーにとっては不可欠です。つまり、エージェントの推論エンジンがバックエンドのコンテキスト、アクション、トリガーをすべて調整して、自然言語による指示に従ってエージェントを誘導します。
このようなシームレスなエクスペリエンスは、すべての水平企業データにわたる一元化されたインデックスなしには実現できません。そのインデックスを忘れるということは、SaaSで発生したのと同じデータサイロをAIのために作り直すこと、あるいは各エージェントの小さくて間もなく時代遅れになるデータセットに自分自身を縛り付けることを意味します。



