






We’re happy to be supporting GPT-5 on the first day it's available. This reflects our ongoing commitment to quickly support the latest AI models so enterprises can evaluate and deploy them in agents that fully understand their enterprise context.
Every Glean customer can try GPT-5 with Agents and directly compare it to other supported models including OpenAI o3, OpenAI GPT-4.1, Claude Sonnet 4, Meta Llama 4, Google Gemini 2.5 Pro, Google Gemini 2.5 Flash, and more. Users can exercise it with the full context of their enterprise data and Agents they’ve already built on Glean.
As part of our ongoing work with OpenAI, Glean received early access to GPT-5 and have been evaluating it for enterprise agentic AI use cases. In this blog, we’ll share our learnings on where and how GPT-5 excels, to help guide how you evaluate it for your own enterprise agents.
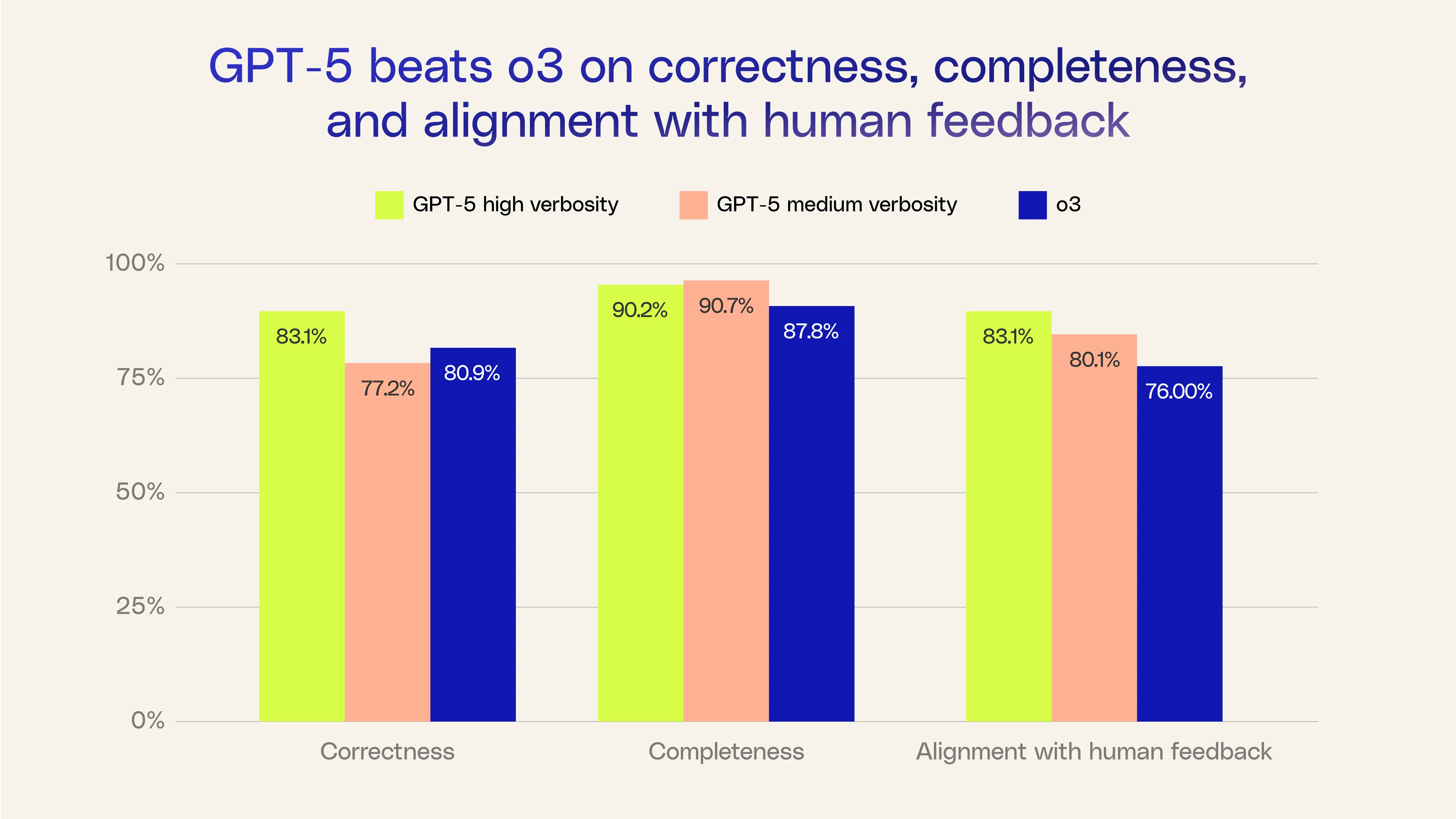
GPT-5 outperforms o3 across the board, on correctness, completeness, and alignment with human feedback
GPT-5 is the first model to fuse general purpose and reasoning capabilities into a single model. When we looked at which models to evaluate GPT-5 against, we looked at the previous generation of OpenAI models; GPT-4.1 was designed for general-purpose tasks, while o3 specialized in reasoning.
At Glean, we’re building Agents and Assistants that adaptively plan, iterating based on past failures or findings. o3 excels at reasoning, being more likely to issue follow-up searches, retry alternative plans, and gather more context when needed. This is exactly the set of skills that helps Glean take on more complex work. This is why we opted to compare GPT-5 to o3 in our evaluation.
At Glean, we have 25+ LLM judges that continuously evaluate our Search, Assistant, and Agents products across a wide range of enterprise work (ie: information seeking, writing, data analysis, coding, etc.). We also evaluate LLMs on these same metrics, helping guide which models we support and how customers can mix and match models.
With so many judges in hand, we used a number of metrics to compare o3 to GPT-5 on Glean’s own production deployment. While we stuck to just our own enterprise use case here due to time constraints, we usually do this on a much larger evalset comprised of real-world customer queries, synthetic queries, and hand-tuned queries.
These metrics are focused on what enterprises really care about when it comes to AI:
- Correctness: Is the output accurate or did it miss the mark? Either as a result of hallucinations or just following the wrong path to the answer.
- Completeness: Did the agent fully accomplish what the user asked? This can be writing an email, creating a Jira ticket, or just responding to all of the aspects specified in the user question.
- Alignment with human feedback: Do the new responses align better with the human feedback we have received on our previous queries?
We saw GPT-5 outperform o3 on these key metrics:

Note: o3 doesn’t have verbosity but we’ve observed a medium verbosity level in our evals.
In the next section of this blog, we’ll delve into why we saw these metrics improve on GPT-5.
GPT-5’s broad tool use beats o3’s deep planning
To help us better understand the differences between o3 and GPT-5, we looked at a couple of investigatory metrics: the number of planning steps and the number of searches run.

What we see in these metrics, as well as by looking at agent plans, is that GPT-5 is inclined to cast a wide net. When it sees a prompt, it quickly gathers information from multiple tools or tries several strategies in parallel. Parallel tool calling is one of the new features in GPT-5 and it knows how to use it.
This means GPT-5 often finds what it needs without having to go through a long chain of intermediate steps. As a result, the “plan” the agent follows (the sequence of actions it takes) is shorter, with fewer steps from start to finish.
In contrast, o3 tends to go deep. It might start with a narrow focus, then follow a chain of reasoning or actions, like searching one source, then drilling down into a specific document, then asking a clarifying question, and so on. This results in more planning steps, as the agent takes a more stepwise, investigative approach.
If we look at the performance results, we can see that the broad tool usage approach adopted by GPT-5 wins. This suggests that effective tool use is becoming a driver of agent performance in the enterprise, often reducing the need for additional planning steps. Ultimately, it underscores that using tools to ascertain context is king; context gives AI models the critical edge they need to tackle work.
Let’s see this play out in an example prompt:
o3 ran an initial company search and hallucinated, incorrectly identifying a single model being used for intermediate steps based on available information.
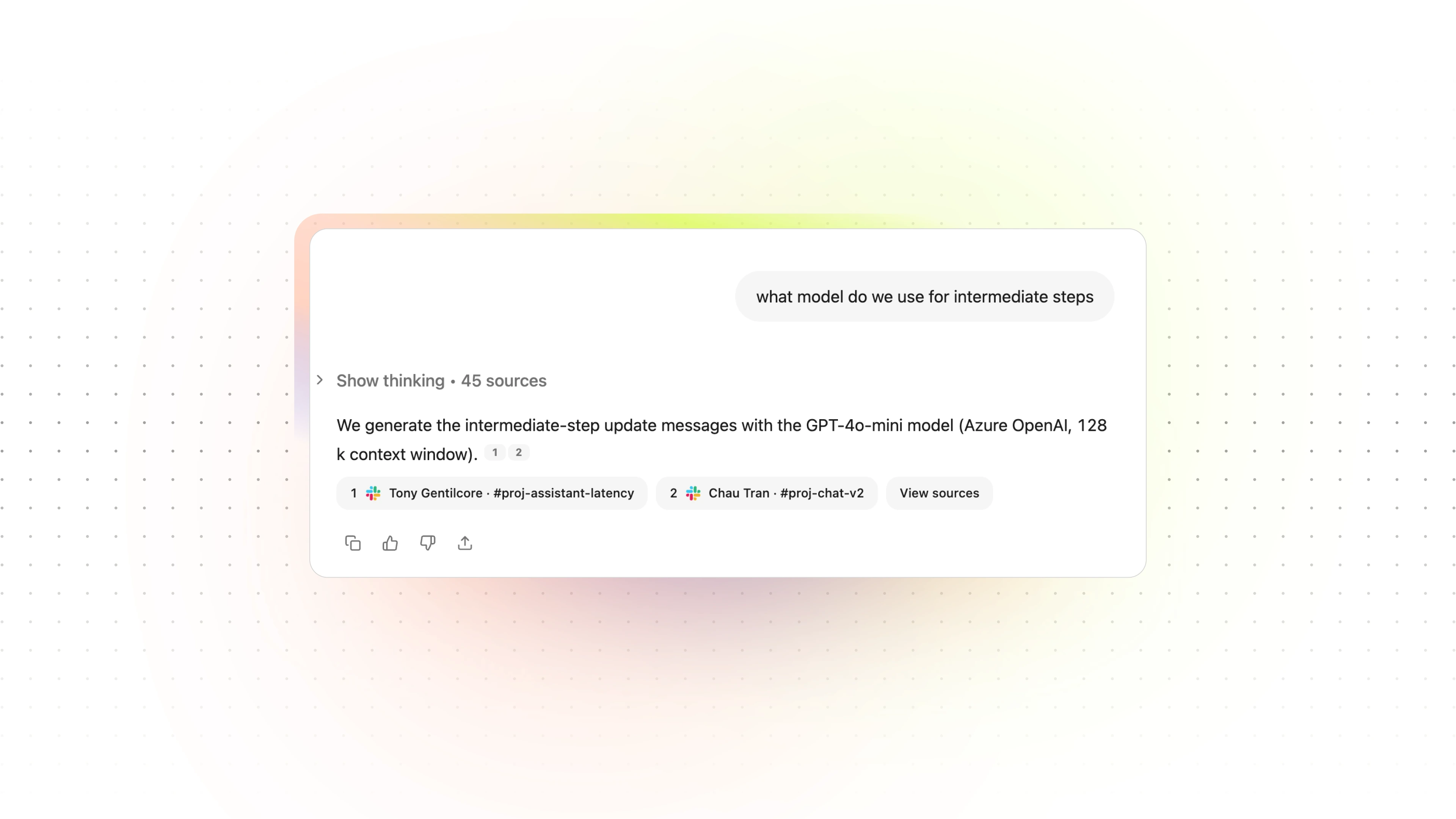
GPT-5 tapped into 110 sources to find the most relevant context, recognized that there are multiple versions of our agentic reasoning architecture, and that customers have the flexibility to choose their own model in agents, surfacing an accurate, complete response.

GPT-5 is better at knowing when to ask for help
One of the cool takeaways from GPT-5 is that it’s able to gauge when to directly answer a question or when to go back to the user and ask follow-up questions.
Let’s see this applied in an example prompt:
As you can see from the result below, o3 went down the rabbit hole of assuming Tony referred to Tony Gentilcore, an engineering Glean co-founder.

But in reality, there are two Tonys at Glean. The two Tonys should receive different answers, given that they both have different roles in the organization. GPT-5 realized this by running a broad search and asking a follow-up question, so it could better understand the best path for answering the question.

We’ve seen follow-up questions become commonplace, both within the Glean Assistant experience and across consumer AI chatbots. Now, we’re reaching the point where the model can determine when it makes sense to get back to the user with the information they need, fast, when it can, and engage in a conversation only when it can’t. This shift makes every conversational experience more valuable.
GPT-5 introduces verbosity, early evals show we’ll be implementing it
Fun fact: When Glean originally built its Assistant experience our engineering team put in place an explicit instruction to use brevity wherever possible. They judged chat quality from their own perspective, preferring to get straight to the point rather than adding extra fluff (their words, not mine). We’ve since removed this setting, recognizing that it limited the ability of the Assistant to both adapt to the task as well as individual preferences.
One interesting addition from GPT-5 is that it introduces verbosity—the ability to range from brief to average to lengthy responses—and can answer the prompt completely even when using medium level verbosity.
Let’s see this in an Assistant query for a product support question:
For this example, o3 provides a response that is well formatted and complete, making it ideal for a help center article.

Now, if I were an engineer preferring more succinct responses, I could apply a low verbosity setting in GPT-5, meeting my preferences without losing out on completeness.

We’re already working on leveraging verbosity controls with end user personalization, both overall and task specific, as well as to curtail the token output on intermediate agent steps. Stay tuned!
GPT-5 overcomes challenges in formatting with o3
While verbosity gives us a new level of control, it also addresses a flaw we saw when switching to o3 from GPT-4.1: decline in response quality. Response quality is a holistic look into how well our Assistant delivers accurate, readable, and user-aligned answers.
That’s because GPT-4.1 is much better at structuring its responses than o3. This is one of the benefits of the new combined approach of general purpose and reasoning models, GPT-5 can deliver both.
We were able to see this not only in sampling the eval results but also in formatting metrics that we run. By looking at formatting applied in responses, we can see that GPT-5 at high verbosity is better able to make use of lists and dividers, giving more structure to the output.

We’re hopeful that by wielding verbosity the right way, we can help to regain some of the response quality metrics lost on o3.
All the models that matter, in one platform
If you haven’t been able to tell, we’re really excited about the performance gains we measured when evaluating GPT-5. Our customers should be excited that we support this new model, and can evaluate it themselves, comparing GPT-5 to leading open source and commercial models for enterprise AI.
While GPT-5 has made strides in reasoning, no single model is perfect for every use case. That’s why Glean continues to give customers model choice, support the latest models, and openly share performance metrics, so you can use these insights to help build the most capable agentic experiences at work.
If you’re ready to see how GPT-5 can help your organization get work done, you can start trying it out in Glean Agents today.



