








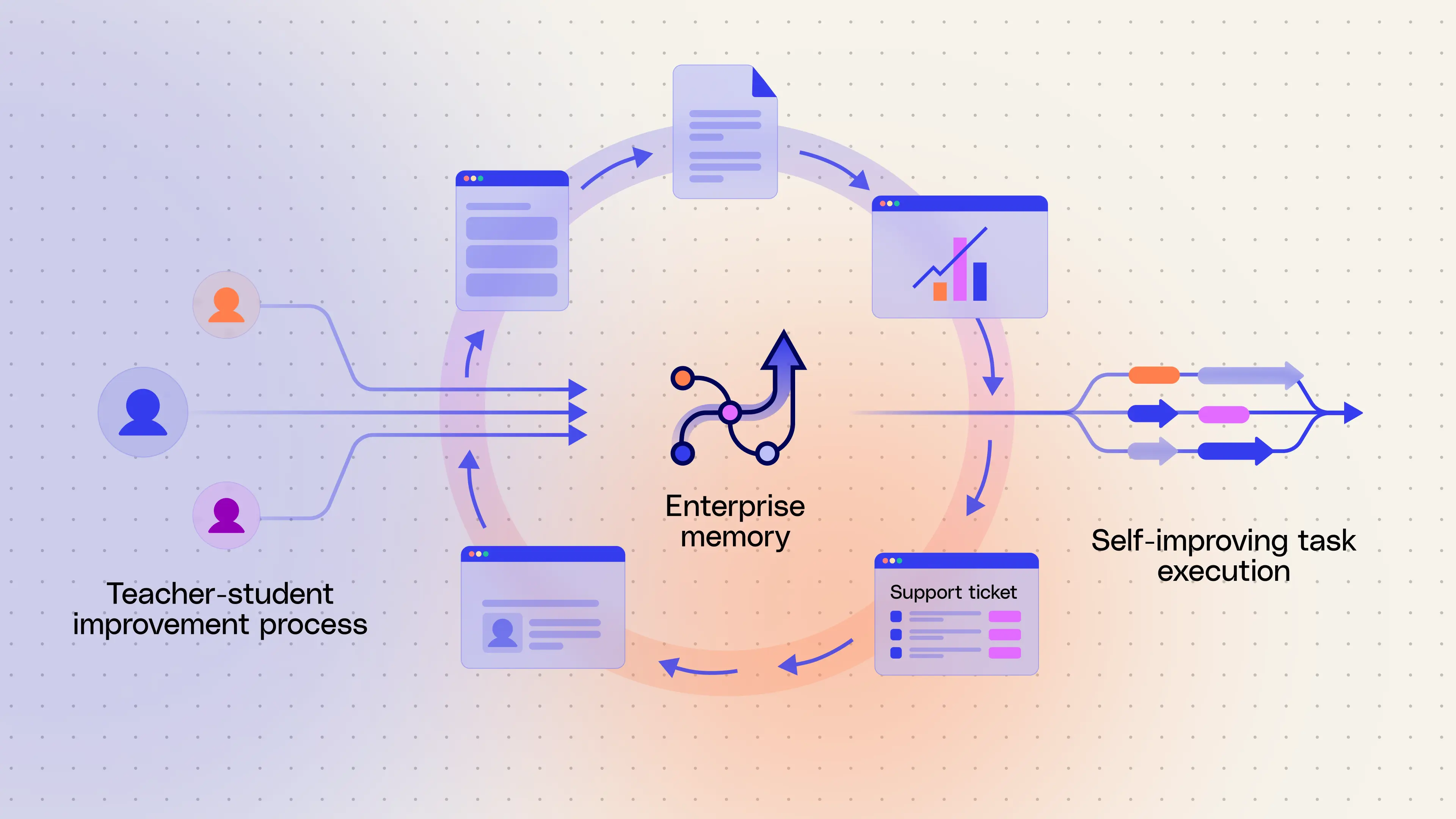

- AI agents need to learn from execution traces instead of treating every task as brand new, because real enterprise expertise comes from understanding workflow patterns, tool sequencing, and failure modes that only emerge through actual task execution.
- Glean’s approach combines offline learning and online retrieval: it compares strong “teacher” and constrained “student” runs, distills reliable strategies into compact memories, and then applies the right memories at runtime to improve correctness, efficiency, and environment-specific performance without fine-tuning.
- For enterprise use, trace learning must be designed around correctness, narrow workflow-level guidance, and strict security boundaries, so Glean validates what it learns, stores reusable deployment-level and private user-level memories separately, and keeps all learning scoped to each customer environment.
Today’s AI agents are powerful, yet they approach every task like a blank slate. Each run is effectively stateless, so the system often repeats the same exploration, tries tools in different orders, occasionally misses key steps, or encounters predictable failure modes. It’s a lot like a new employee learning a process for the first time. Even when the agent eventually succeeds, the path it took and the mistakes along the way are not retained, so the next similar task starts from scratch.
To deliver on their promise, agents need to learn more like humans do. They need to gain exposure to real tasks, learning from every success and failure, and carrying that hard-won context forward.
That’s where traces become critical. A trace is a record of how a task was actually executed, including what tools were used, in what order, with what parameters, and what the outcome was.
In enterprise environments, traces are especially valuable because the hardest part of the problem isn’t tool usage, it’s workflow understanding: which systems are actually authoritative, how multiple tools are combined across steps, implicit conventions and sequencing, and which patterns only show up in real usage.
These patterns don’t live in model training data. They only emerge through execution.
Trace learning turns those executions into a feedback loop. Instead of memorizing entire trajectories, the system extracts the useful parts: what strategy worked, what failed, and what should be done differently next time. Over time, this allows the agent to:
- avoid repeating known failure patterns
- reuse effective tool sequences and parameter choices
- adapt to environment-specific workflows
- improve performance without fine-tuning or large instruction sets
This is why traces are more than just useful for observability. When agents learn from them, they can move from one-off task execution to building real, environment-specific expertise.
In this blog, we’ll share Glean’s approach to trace learning, including how we design for correctness, focus on workflow-level tool strategies , and ground everything in permissions and governance.
How trace learning improves task performance
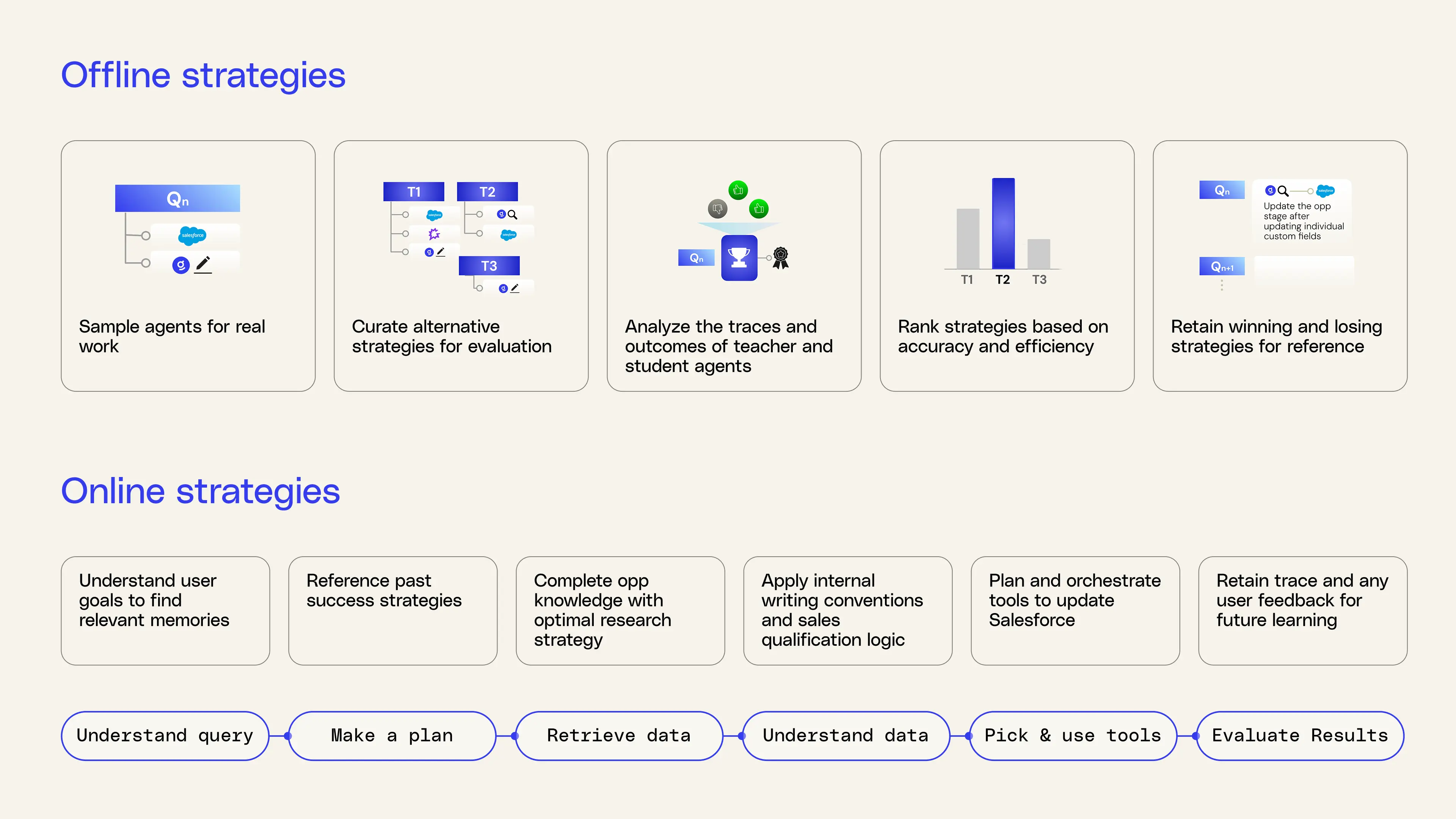
At a high level, trace learning has two components:
- Offline learning, which mines strategies from historical traces.
- Online application, which retrieves and applies those strategies at runtime.
You can think of it as a loop where every task makes agents stronger.
Offline learning: exploring alternatives safely
During offline learning, Glean samples real traces based on agentic tasks from your deployment. It then learns from those traces by:
- Running a strong “teacher” agent with a high reasoning budget and broad tool access to act as a high-quality reference for what “good” execution looks like on a task.
- Comparing multiple “student” agent traces that operate under real production constraints, including tighter budgets, stricter tool sets, and latency limits, to understand how the agent behaves under real-world constraints.
- Scoring each strategy. The combination of multiple students and a teacher creates a baseline for evaluating which strategies perform better or worse. We select strategies that stand out from their group based on correctness, tool-calling behavior, execution efficiency, and alignment with user feedback.
- Distilling the best strategies from top-performing students into compact natural‑language memories that will guide future agent runs.
Online application: applying the right memories at runtime
When a someone submits a query to Glean, it:
- Understands the goal
- Retrieves relevant memories based on the task pattern
- Adapts the agent plan using those memories before execution
- Executes the plan using the same memories in context
For example, on a query like "Update all my open Salesforce opportunities," Glean may use memories such as:
- Do not move StageName if any MEDDICC field is blank or only contains boilerplate text like “TBD” or “Follow up next week”.
- When MEDDIC fields are updated, prefer updating those fields in a separate write before changing StageName.
- For long text narrative fields such as Customer_Narrative__c, append a new dated section instead of overwriting existing content.
- When changing a Salesforce opportunity stage, first use the ‘Update Salesforce opportunity’ tool to fill in each key field, including Amount, CloseDate, ForecastCategory, MEDDIC, Next Step, if that field is blank or more than 14 days old.
- When researching fewer than 10 opportunities, use Glean search with the Salesforce app filter and the ‘Opportunity’ document type filter instead of the Salesforce Object Query Language (SOQL) search tool.
- When researching a large number of opportunities for analytics, use SOQL search while selecting the custom fields `ARR__c`, `TechStack__c`, `Partner__c`, and `SeatCount__c` at a minimum, along with standard opportunity fields.
These memories were learned from success patterns and failure modes that were encountered during the offline phase of trace learning in Glean’s own deployment.
Recent work in trace learning
Recent work on trace learning converges on a shared idea: agents improve when they can retain and reuse structured experience from real tasks. Instead of relying only on static training, these approaches treat past executions as a source of learning, allowing agents to adapt to environments that are complex, evolving, and highly context-dependent.
Dynamic Cheatsheet is one of the earlier formulations of this idea. It frames memory as a self-curated, adaptive layer, where the agent decides what to keep or discard based on usefulness. The key insight is that effective memory needs to be both specific enough to be actionable and abstract enough to generalize. Rather than storing full trajectories, the system distills traces into concise natural language guidance that captures what mattered in a way that can transfer across similar tasks. This makes memory more than just a record of the past, but something that can reliably guide future behavior.
Agentic Context Engineering (ACE) builds on this idea by moving to structured playbooks. ACE aggregates patterns across many traces into reusable strategies that encode when a strategy applies, how to sequence steps, which tools to prioritize, and how to handle common failure modes. This shifts the system from remembering what happened to learning what should be done.
ReasoningBank uses contrastive learning to improve those strategies. Instead of only reinforcing successful traces, it explicitly compares successful and failed executions to understand where behavior diverged. By analyzing what changed between a failure and a success, such as tool choice, ordering, or intermediate reasoning, the system can isolate which decisions actually mattered.
Glean’s trace learning builds on these ideas but adapts them for enterprise environments. Instead of relying on the results of a single teacher trace alone, Glean aggregates signals across many executions and enforces stricter validation before learning. This makes the learned guidance more accurate, while still letting it generalize across similar tasks within a customer’s deployment.
How we designed trace learning for the enterprise
Trace learning is an accuracy problem as much as a learning problem
Building enterprise memory was as much a design problem around accuracy as it was a learning problem. For enterprise AI, the right answer usually isn’t available in public data, and agent outputs aren’t always directly verifiable.
We found that a single teacher trace, even with the highest reasoning effort, wasn’t reliable enough on its own. So we moved to a stricter setup: extract assertions across responses, check for agreement, verify conflicts using Glean Search, and avoid learning altogether when inconsistencies cannot be resolved.
In offline learning, we run a high-reasoning teacher trace and compare it against multiple alternative executions. To determine what the system should actually learn, we extract factual claims from multiple responses, check whether they agree, and only keep a canonical answer when the outputs are consistent or can be verified with additional tools. If the inconsistency cannot be resolved, we generate no learning at all. This approach is more careful and selective about what it learns from, compared to systems that just trust their own outputs or reuse past runs as-is.
Because accuracy matters, Glean is deliberate about what it learns from. The current trace-learning flow selects high-quality, representative queries that are likely to recur, and it uses multiple classifiers plus high-confidence intent checks rather than trying to learn from every possible query. That keeps the resulting strategies smaller, cleaner, and more trustworthy as runtime guidance.
Just as with ReasoningBank’s approach, we also learn from both successes and failures, not just from the runs that happened to end well. The goal is to expose the model to diverse traces so it can understand multiple paths to a solution, see where execution breaks down, and distill more useful lessons than a single golden path would provide. We’re ensuring that over time the agent will become increasingly more accurate in how it tackles tasks.
Store intentionally narrow tool strategies that generalize across related tasks
When we designed trace learning, we made a conscious decision to store learnings that were intentionally narrow. The goal was to capture guidance like “in this situation, prefer this strategy” rather than prescribing exact sequences or abstracting too broadly, so the learnings remain actionable while still generalizing across related tasks.
In an environment with hundreds of connectors and actions, the challenge is not just finding the right tool, but knowing how to use tools together effectively. Agents need to move beyond individual actions and learn reusable patterns of execution, such as when to parallelize versus sequence tool calls, when one system is authoritative for analytics versus record-level detail, and when multiple tools should be combined into a single workflow. This matters even more in enterprise settings, where the difficulty isn’t tool availability, but understanding how work actually gets done within a specific organization.
In other words, trace learning shifts the focus from “which tool to call” to “how to accomplish a task across tools.”
Capturing these workflow-level patterns has another important benefit. It reduces the action space at runtime by clustering tools into higher-level primitives, while still providing practical guidance on how those tools should be used together. Instead of navigating dozens of tools in isolation, agents can operate at the level of meaningful workflows, such as “update release notes,” tailored to how that task is actually performed within a given enterprise.
These benefits of trace learning extend to MCP-based tools, where limited context and instructions make learning from execution traces even more valuable.
Split learnings into deployment and user levels to securely capture individual preferences
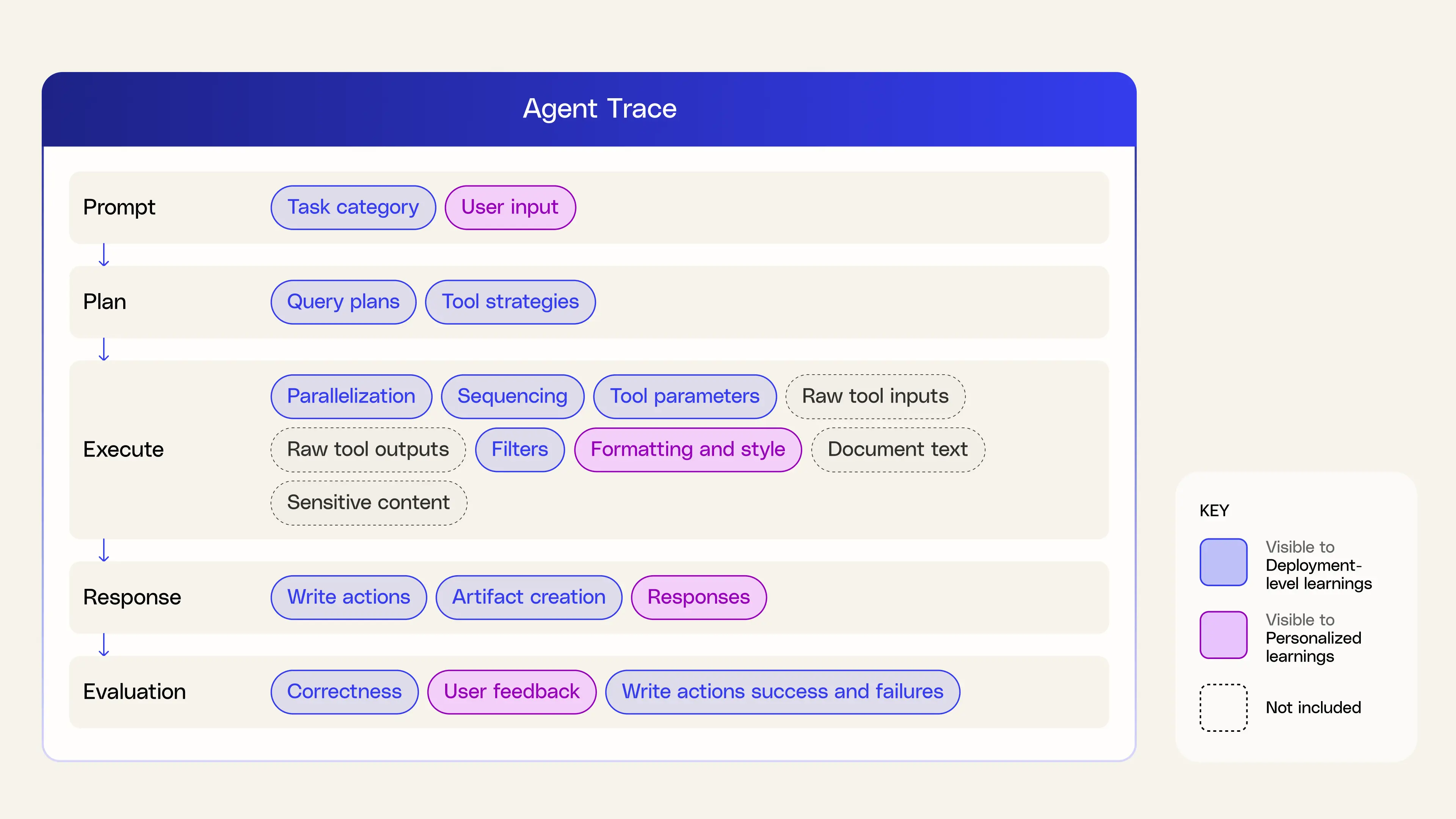
Memory is designed with safety in mind. Learning happens at the deployment or user level and is never generalized across enterprises. All learnings are stored externally to models with no information retained outside a Glean deployment. Actions that would write to apps like Google Drive, Salesforce, Jira, Asana, or Slack are replayed in a shadow path without touching production data. That lets us learn from trying out realistic end‑to‑end flows without impacting customer data.
We structure memory across two levels: deployment-level strategies that are shared within a company, and personalized learnings that are only visible to the individual user.
- Deployment-level learning focuses on how tools are used, not on the underlying data. We store only what generalizes, such as tool names, sequencing patterns, parameter templates, and query types. We explicitly exclude user prompts, document content, raw tool outputs, titles, IDs, emails, and other sensitive fields.
- User-level learning is private to each individual. It captures preferences such as content templates and formatting for documents like pull requests, release notes, and status updates, along with communication styles for creative or customer-facing work.
Our early versions of trace learning only stored deployment-level strategies so we could prioritize security and shared workflow understanding. But doing that also meant we initially missed user-level memory, where templates, formatting, and individual work preferences matter most. We later found these user-level strategies had a significant impact on performance, which led us to adopt a two-level memory structure.
Expanding trace learning beyond agent runs
Trace learning is a key step toward making agents that improve with experience. By learning from real executions, agents move beyond one-off task completion and start accumulating practical knowledge about what works, what fails, and how to approach similar problems more effectively over time.
But traces aren’t limited to agent runs. They also exist across enterprise systems as records of how work actually gets done, spanning documents, actions, and interactions across tools. The next step is connecting these layers. Agent traces show how tasks are executed, while enterprise traces show how work flows across the organization. Together, they open the door to a deeper understanding of workflows — that’s where context graphs come in.
Learn more about self-improving task execution by booking a demo today!



