Overcoming challenges in maintaining current search indexes
Modern enterprises face an unprecedented challenge: maintaining search capabilities that match the velocity of data creation across their organizations. As companies scale from hundreds to thousands of employees, the gap between when information is created and when it becomes discoverable through search can mean the difference between seizing opportunities and missing them entirely.
The explosion of SaaS applications has fragmented organizational knowledge across dozens of systems, each generating content at different rates and in various formats. Financial services firms process millions of transactions daily, technology companies update documentation continuously, and customer service teams create new support tickets every minute — all while employees expect instant access to the latest information.
Search indexes are specialized data structures that store and organize content in formats optimized for rapid retrieval. Think of them as sophisticated filing systems that pre-process information to enable split-second searches across millions of documents. The global knowledge management market, valued at $773.6 billion in 2024, is projected to reach $3.5 trillion by 2034. This explosive growth reflects the growing recognition of search and knowledge accessibility as strategic business imperatives. Unlike simple database queries that scan through records sequentially, search indexes use inverted structures — similar to how a book index lists topics with their corresponding page numbers — to locate relevant content instantly.
This constant flux of data demands sophisticated approaches to search index management that go beyond traditional batch processing methods. And the stakes are high: enterprise search systems demonstrate only 10% first-attempt success rates compared to Google's 95% accuracy, creating a 9.5 times performance gap; organizations with inadequate search capabilities lose 45% productivity, with workers spending an average of 3.2 hours weekly searching for information. Organizations that fail to keep their search indexes current risk creating information silos where critical insights remain hidden, decision-making slows, and productivity suffers across every department from engineering to human resources.
What are search indexes and why do they need constant updates?
Search indexes are specialized data structures that store and organize content in formats optimized for rapid retrieval. Think of them as sophisticated filing systems that pre-process information to enable split-second searches across millions of documents. Unlike simple database queries that scan through records sequentially, search indexes use inverted structures — similar to how a book index lists topics with their corresponding page numbers — to locate relevant content instantly.
At their core, search indexes transform raw data into searchable tokens, create mappings between terms and documents, and maintain complex scoring algorithms to rank results by relevance. Modern implementations like Elasticsearch and Apache Solr build upon the Lucene search engine, storing data in segments that can be searched in parallel while maintaining sophisticated relevance scoring based on term frequency and document relationships.
The imperative for continuous updates
The consequences extend beyond operational efficiency. Outdated indexes directly impact customer experience when support teams can't find recent interactions or when sales representatives lack visibility into the latest contract terms. Every minute of delay between data creation and searchability represents potential revenue loss, decreased customer satisfaction, and reduced competitive advantage. Companies relying on outdated data to train machine learning models experience an average 6% global revenue loss—approximately $406 million—due to inaccurate predictions and suboptimal model performance. In healthcare, medical errors attributable to outdated patient information represent the third leading cause of death in the United States. Organizations that maintain fresh indexes — updating within seconds or minutes rather than hours or days — demonstrate measurably better performance across key metrics including time-to-resolution, deal velocity, and operational efficiency.
Without regular updates, search results quickly become unreliable. Employees searching for the latest product specifications might receive outdated versions, leading to costly errors. Support agents looking for recent customer issues could miss critical patterns emerging in real-time. The degradation isn't linear — even a few hours of staleness can render search results practically useless for time-sensitive operations like incident response or market analysis.
Business impact of index freshness
Real-time business decisions depend on accessing the most current data available. In financial services, traders need immediate visibility into market movements and risk exposures. Manufacturing operations require instant access to production metrics and quality control data. When search indexes lag behind actual data state, organizations operate with incomplete information, making decisions based on yesterday's reality rather than today's truth.
Navigating the intricacies of data pipelines in today's enterprises demands precision and adaptability. Data streams from diverse origins: structured databases, unstructured files, and live data feeds. Organizations leveraging real-time analytics report 15% revenue growth and 23% higher efficiency compared to those relying on outdated data, yet 80% of enterprises still depend on stale data for critical decisions despite heavy investments in data infrastructure. Each source presents unique formatting challenges, necessitating sophisticated transformation techniques to ensure data coherence for indexing.
Understanding the complexities of modern data pipeline management
Navigating the intricacies of data pipelines in today's enterprises demands precision and adaptability. Data streams from diverse origins: structured databases, unstructured files, and live data feeds. Each source presents unique formatting challenges, necessitating sophisticated transformation techniques to ensure data coherence for indexing.
Orchestrating the pipeline
Coordinating data pipelines requires meticulous attention to extraction, transformation, and loading (ETL) processes. Each data source operates on distinct schedules, demanding a flexible orchestration approach to maintain consistent data flow.
- Integrated staging: Harmonizing data extraction with transformation ensures timely preparation for indexing, despite variations in source availability.
- Dynamic scheduling: Systems must dynamically adjust to the timing and frequency of data updates, incorporating strategies to accommodate late-arriving data without disruption.
Handling errors and monitoring health
The complexity of managing numerous data streams necessitates robust error-handling frameworks. Identifying and rectifying issues promptly is crucial to prevent cascading failures and maintain pipeline integrity.
Monitoring the health of data pipelines involves comprehensive metrics beyond basic checks:
- Throughput optimization: Continuously evaluating processing speeds to quickly identify and address bottlenecks.
- Latency optimization: Ensuring minimal delays from data ingestion to indexing, maintaining the freshness of search results.
- Failure diagnostics: Analyzing error patterns to proactively resolve underlying issues.
Balancing resources
Resource management is a delicate equilibrium between efficiency and cost. Enterprises must optimize resource allocation to support real-time indexing without excessive expenditure.
- Scalable infrastructure: Utilizing cloud solutions to dynamically scale resources in response to demand, achieving cost-effective performance.
- Efficient load distribution: Spreading processing tasks across multiple nodes to prevent bottlenecks and enhance system resilience.
By mastering these complexities, enterprises can maintain responsive and current search capabilities, driving informed decision-making at every organizational level.
Key challenges in keeping search indexes synchronized
Maintaining synchronized search indexes in a dynamic enterprise environment requires overcoming several critical challenges. These difficulties range from managing vast data influxes to ensuring technical infrastructure can handle the load.
Data volume and velocity issues
Organizations face the challenge of processing extensive amounts of data, requiring efficient indexing to maintain rapid search capabilities. Handling unpredictable data surges without compromising performance is crucial. As indexes grow with new entries, efficiently managing storage becomes vital. Additionally, identifying duplicates across expansive datasets is essential for maintaining index integrity.
Technical infrastructure limitations
The infrastructure supporting indexing operations often encounters constraints. Bandwidth limitations can hinder data transfer, slowing the indexing process. CPU and memory capacities must be optimized during resource-intensive tasks to prevent system strain. Disk I/O limitations can affect both indexing and retrieval speeds, necessitating streamlined operations. Balancing resources between indexing activities and query responses ensures consistent performance.
Data consistency and accuracy concerns
Reliability in search results depends on maintaining data consistency and accuracy. Ensuring consistent updates across distributed indexes prevents discrepancies. Addressing version conflicts from concurrent document updates is essential. Preserving referential integrity across related datasets guarantees coherent search outputs. Managing partial updates carefully prevents data corruption and maintains the overall reliability of the index.
These challenges underscore the need for strategic approaches to keep search indexes current, precise, and effective in a complex data environment.
Real-time indexing strategies and implementation approaches
Enterprises aiming for immediate search capabilities need robust real-time indexing methods. By adopting targeted indexing, companies focus on updating only the changed documents, which streamlines operations and enhances data availability.
Utilizing source-level change detection and concurrent processing
Employing source-level change detection methods ensures that any data modifications trigger swift updates to search indexes. This precision minimizes delays and maintains data accuracy. Concurrent processing boosts efficiency by allowing simultaneous management of various data inputs, optimizing overall system performance.
- Source-level precision: Detecting changes directly at their origin ensures timely updates, enhancing data accuracy.
- Concurrent management: Handling multiple data streams concurrently maximizes throughput and maintains high system efficiency.
Custom index strategies and seamless data integration
Creating specialized indexes for different update cadences—such as real-time and scheduled updates—enables enterprises to manage resources effectively while keeping critical data current. Implementing continuous data integration ensures a steady flow of updates, maintaining the relevance of search results.
- Specialized indexing: Tailored indexes align with specific data update requirements, optimizing resource use and data relevance.
- Continuous integration: Seamless data flow maintains up-to-date indexes, ensuring immediate accessibility of new information.
Enhancing resilience with incremental adjustments and secure pipelines
Incremental adjustments refine the indexing process by focusing on data changes, thus reducing unnecessary operations. Secure pipeline designs provide resilience, allowing recovery from disruptions without data loss, ensuring reliable operations.
- Incremental refinement: Concentrating on specific data changes optimizes indexing efficiency, reducing redundant tasks.
- Secure systems: Resilient pipelines ensure data integrity and continuity, maintaining steady operations even during setbacks.
Best practices for data synchronization techniques
Effective data synchronization is crucial for maintaining the integrity and relevance of search indexes. Establishing clear ownership for each content type ensures consistency and accountability. By designating authoritative sources, organizations can prevent conflicts and discrepancies, ensuring that the most reliable data populates search indexes.
Maintaining data freshness and precision
Implement advanced version control systems to track the most current data iterations. This approach guarantees that only the latest information enters the index, preserving its relevance. Additionally, utilizing advanced algorithms for change detection allows organizations to identify modifications swiftly, ensuring prompt updates.
- Version control systems: These systems prioritize current data, keeping content up-to-date.
- Algorithmic change detection: Advanced methods ensure timely updates by quickly identifying alterations.
Designing for adaptability and recovery
Developing flexible index architectures supports various data formats, facilitating seamless data integration. This adaptability is vital for managing different datasets without impacting performance. Incorporating robust recovery protocols further enhances system resilience, allowing smooth restoration from synchronization errors without data compromise.
- Flexible architectures: Versatile designs support multiple formats, improving integration.
- Robust recovery protocols: Effective procedures ensure data preservation during system recovery.
Addressing conflicts and enhancing monitoring
Implement dynamic strategies for resolving update conflicts, ensuring data consistency across the board. Regularly assess synchronization latency to gain insights into system efficiency, enabling proactive adjustments. By setting precise alert thresholds, organizations can swiftly respond to irregularities, maintaining the stability of the indexing process.
- Dynamic conflict resolution: Techniques ensure consistent data during simultaneous updates.
- Latency assessment: Monitoring delays provides insights for maintaining system efficiency.
Optimizing index update frequency and performance
Optimizing the frequency of index updates is crucial for maintaining relevant data while managing system resources effectively. This involves a strategic approach to keeping information fresh without overloading infrastructure.
Determining optimal refresh intervals
Understanding query demand helps pinpoint which data elements need regular updates. By studying user interactions and data usage, organizations can focus resources efficiently. It's essential to balance the need for current data with the limitations of processing power, ensuring updates are timely yet resource-conscious.
- Adaptive refresh rates: Tailoring refresh rates according to the volatility and significance of content allows for prioritized resource allocation.
- Forecasting demand: Using analytics to predict when data updates will peak helps prepare infrastructure to handle increased activity, maintaining performance during critical periods.
Performance optimization techniques
Enhancing indexing efficiency requires minimizing workload while ensuring data accuracy. Grouping similar updates streamlines processing, enabling systems to manage large datasets effectively.
- Smart caching: Utilizing strategic caching to prevent unnecessary re-indexing reduces workload and enhances speed.
- Data compression: Applying compression to lower data transfer volumes optimizes bandwidth, improving overall system efficiency.
Refining index configurations boosts both access and storage efficiency, aligning with organizational goals for optimal performance.
- Parallel processing: Distributing indexing tasks across multiple systems accelerates data handling, ensuring swift integration and retrieval.
These approaches empower organizations to maintain effective search capabilities, meeting user needs without compromising on system efficiency.
Advanced content crawling and ingestion strategies
To stay ahead in a fast-paced data environment, enterprises need sophisticated crawling and ingestion strategies. By implementing adaptive crawling, companies can tailor the frequency of data retrieval to align with specific content change patterns, thus ensuring timely updates without unnecessary strain on resources.
Smart crawling and discovery tools
To uphold system efficiency, it is crucial to regularly assess query performance and identify potential slowdowns. When artificial delays are introduced into search responses, users of previously fast systems demonstrate measurably altered behavior, issuing fewer queries and examining results less thoroughly. Users are significantly more likely to perform clicks on result pages served with lower latency, even when content is identical. Implementing automated verification processes enhances system reliability, detecting and addressing inconsistencies swiftly. This proactive approach ensures uninterrupted and effective search functionality.
- Relationship mapping: Understanding document connections helps prioritize vital updates, ensuring a cohesive data landscape.
- Protocol efficiency: Utilizing sitemaps ensures no critical content is missed during crawling operations.
Custom integrations and data validation
Developing custom connectors for proprietary data sources and APIs is essential for seamless data integration. This approach ensures that unique datasets are accessed efficiently. Content fingerprinting further optimizes this process by validating data uniqueness, preventing redundant indexing.
- Bespoke data access: Customized connectors ensure smooth interaction with diverse sources, enabling thorough indexing.
- Data uniqueness: Fingerprinting techniques verify content originality, streamlining the indexing process.
Predictive analytics and compliance
Machine learning models can forecast content changes, directing crawling efforts toward areas with the highest impact. This proactive strategy enhances efficiency by focusing on critical updates. Additionally, designing crawlers to respect rate limits while maximizing data throughput ensures compliance with external constraints, maintaining ethical standards in data handling.
- Proactive crawling: Predictive analytics guide resources to crucial updates, enhancing data accuracy.
- Ethical throughput: Rate-aware crawlers optimize performance without exceeding server capacities.
By adopting these advanced strategies, organizations can ensure their search capabilities remain robust and aligned with the evolving data landscape.
Monitoring and maintaining search index health
Ensuring the robustness of search indexes involves a multifaceted approach. Implementing advanced AI-driven monitoring techniques is essential for tracking the quality and timeliness of indexed data. By measuring the delay between content creation and indexing, organizations can maintain a high standard of data relevancy.
System performance and reliability
To uphold system efficiency, it is crucial to regularly assess query performance and identify potential slowdowns. Implementing automated verification processes enhances system reliability, detecting and addressing inconsistencies swiftly. This proactive approach ensures uninterrupted and effective search functionality.
- Automated verification processes: Detect issues early, maintaining seamless operations and system stability.
- Performance assessment: Regular checks optimize query handling, ensuring swift and reliable search results.
Insightful analytics and responsive systems
Developing real-time analytics dashboards enables enterprises to gain immediate insights into indexing operations, highlighting throughput and error trends. Establishing responsive alert systems ensures that any deviations from expected patterns are promptly managed, sustaining system health and functionality.
- Real-time dashboards: Provide immediate visibility into system operations, facilitating quick issue resolution.
- Responsive alerts: Quickly address anomalies, protecting the integrity of search operations.
Continuous improvement and strategic enhancement
Ongoing review of search logs allows for the identification of indexing gaps, ensuring comprehensive data coverage. Regular updates and strategic enhancements to index configurations support scalability and efficiency, keeping pace with data growth and evolving organizational needs.
- Comprehensive review: Identifies missing data, enhancing the breadth and depth of indexed content.
- Strategic enhancements: Regular updates ensure scalability, supporting efficient data processing and retrieval.
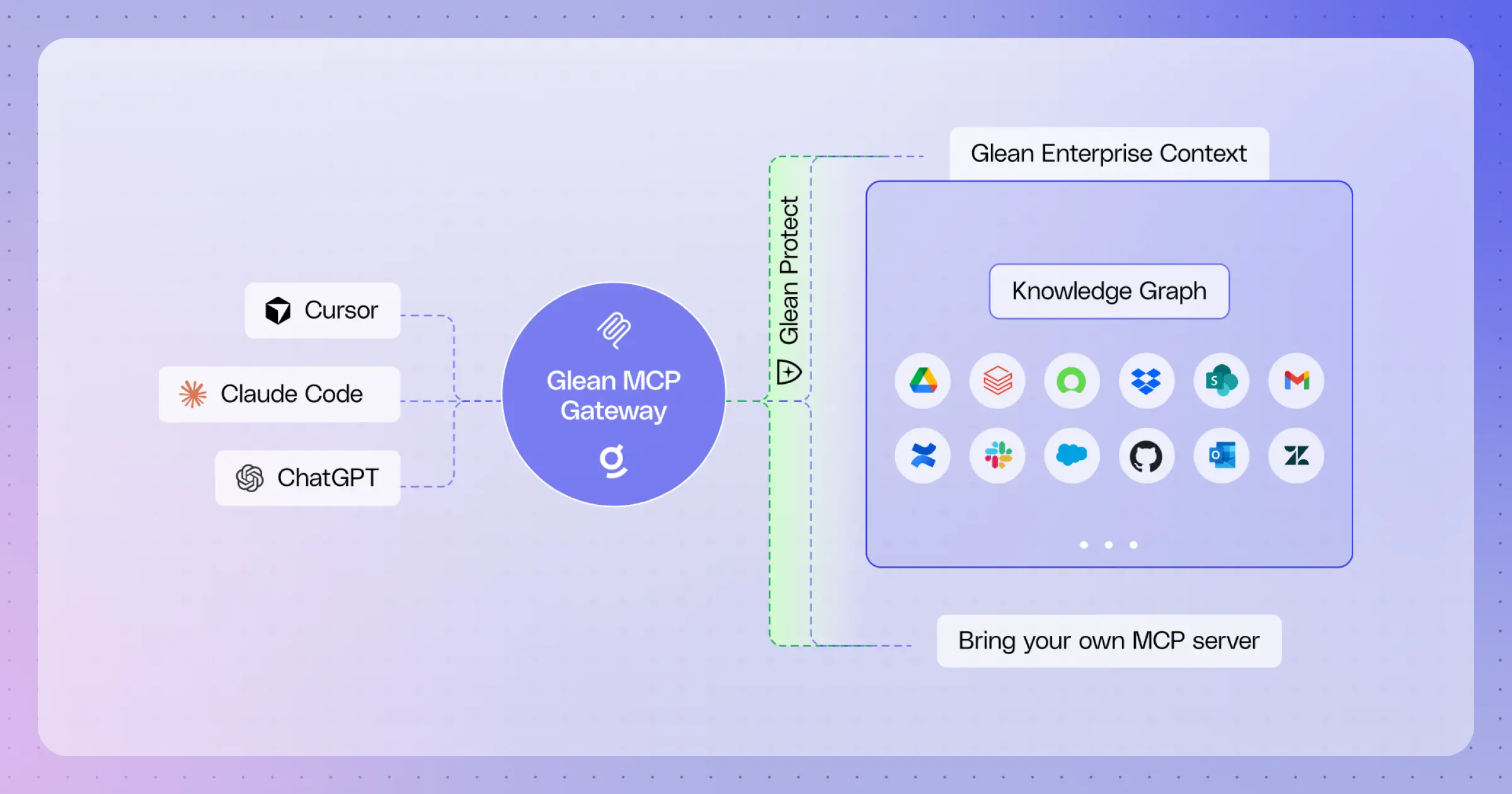
As data volumes continue to explode and real-time access becomes non-negotiable, maintaining current search indexes will only grow more critical to enterprise success. The strategies and techniques we've explored provide a foundation for building resilient, responsive search capabilities that keep pace with your organization's evolving needs. Ready to see how AI-powered search can eliminate these indexing challenges entirely? Request a demo to explore how Glean and AI can transform your workplace.